一个软件工程师的深度学习入门实录:从训练第一个模型到理解微调与蒸馏
- 写在前面
- PyTorch 和 TensorFlow 是什么?
- 深度学习核心概念的软件工程类比
- 动手:训练第一个模型
- 训练好的模型跑在哪?
- 为什么需要 GPU?
- 微调(Fine-tuning)
- 蒸馏(Distillation)
- 训练 AI 模型的工作量分布
- 完整代码

写在前面
作为一个软件工程师,我一直对深度学习的概念停留在"知道但不理解"的阶段。PyTorch、TensorFlow、微调、蒸馏这些词天天看到,但到底是什么、怎么工作的,一直没有真正搞清楚。
这篇文章记录了我从零开始动手训练模型的过程,用软件开发的概念来类比深度学习的核心知识点。如果你和我一样是软件工程师背景,想搞懂这些东西,这篇文章应该能帮到你。
PyTorch 和 TensorFlow 是什么?
一句话:它们就是深度学习领域的开发框架,类似于 Web 开发中的 Spring 和 Django,只不过不是用来做 Web 应用的,而是用来构建和训练 AI 模型的。
PyTorch 由 Meta 开发,采用动态计算图,写起来更像普通 Python 代码,调试方便,目前在学术研究领域最受欢迎。
TensorFlow 由 Google 开发,早期用静态计算图,2.0 之后也支持动态图。它的优势在于生产部署生态更成熟(TensorFlow Serving、TensorFlow Lite 等)。
如果刚入门,大多数人推荐从 PyTorch 开始。
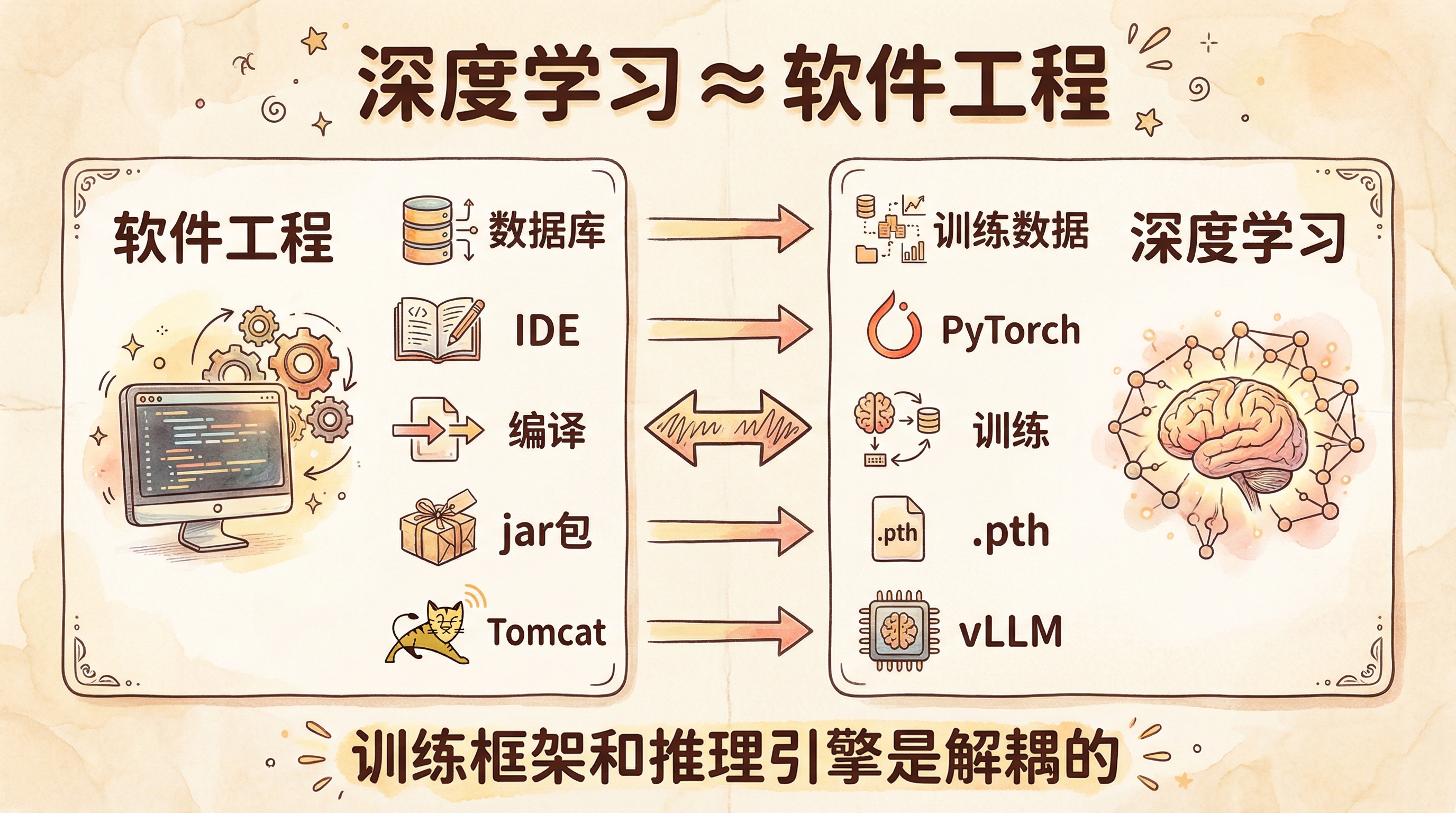
深度学习核心概念的软件工程类比
在动手之前,先用我们熟悉的概念建立映射:
| 深度学习概念 | 软件工程类比 |
|---|---|
| 训练数据 | 数据库里的数据 |
| 模型 | 程序逻辑(但是从数据中自动学出来的) |
| 训练过程 | 编译 + 反复跑测试直到通过 |
| 部署推理 | 应用上线 |
| 模型文件(.pth) | 编译产物(jar / Docker 镜像) |
| PyTorch / TensorFlow | IDE + 编译器 |
| 推理引擎(vLLM 等) | 生产环境运行时 |
一个关键认知:训练框架和推理引擎往往是解耦的。很多公司用 PyTorch 训练,然后把模型转换格式部署到专门的推理引擎上。就像你在 IDE 里写代码编译,但最终跑的是 jar 包在 Tomcat 上,而不是跑在 IDE 里。
动手:训练第一个模型
选的是深度学习的 "Hello World"——MNIST 手写数字识别。在 Mac 上用 PyTorch 完成。
环境准备
brew install python@3.12 # PyTorch 暂不支持 3.14
mkdir ~/mnist-demo && cd ~/mnist-demo
python3.12 -m venv venv
source venv/bin/activate
pip install torch torchvision
注:
torch就是 PyTorch 的包名,torchvision是配套的图像处理库。
模型结构
class SimpleNet(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.layers = nn.Sequential(
nn.Linear(28 * 28, 128), # 第1层:784 → 128
nn.ReLU(), # 激活函数
nn.Linear(128, 64), # 第2层:128 → 64
nn.ReLU(),
nn.Linear(64, 10), # 第3层:64 → 10(输出0-9)
)
这里每个 nn.Linear 就是一层。层数和大小不是固定的,是你自己设计的,相当于系统的架构设计:
- 28×28 和 10 是由数据决定的(输入图片 28×28 像素,输出 0-9 十个数字),不能随便改
- 128 和 64 是你自己定的,可以改成 256、512,想加几层加几层
- ReLU 是激活函数,给模型引入非线性能力,没有它不管堆多少层数学上都等价于一层
不同场景的模型规模差别很大:我们这个 3 层、10 万参数;ResNet 上百层、几千万参数;GPT-4 据传上百层、万亿参数。
训练模板
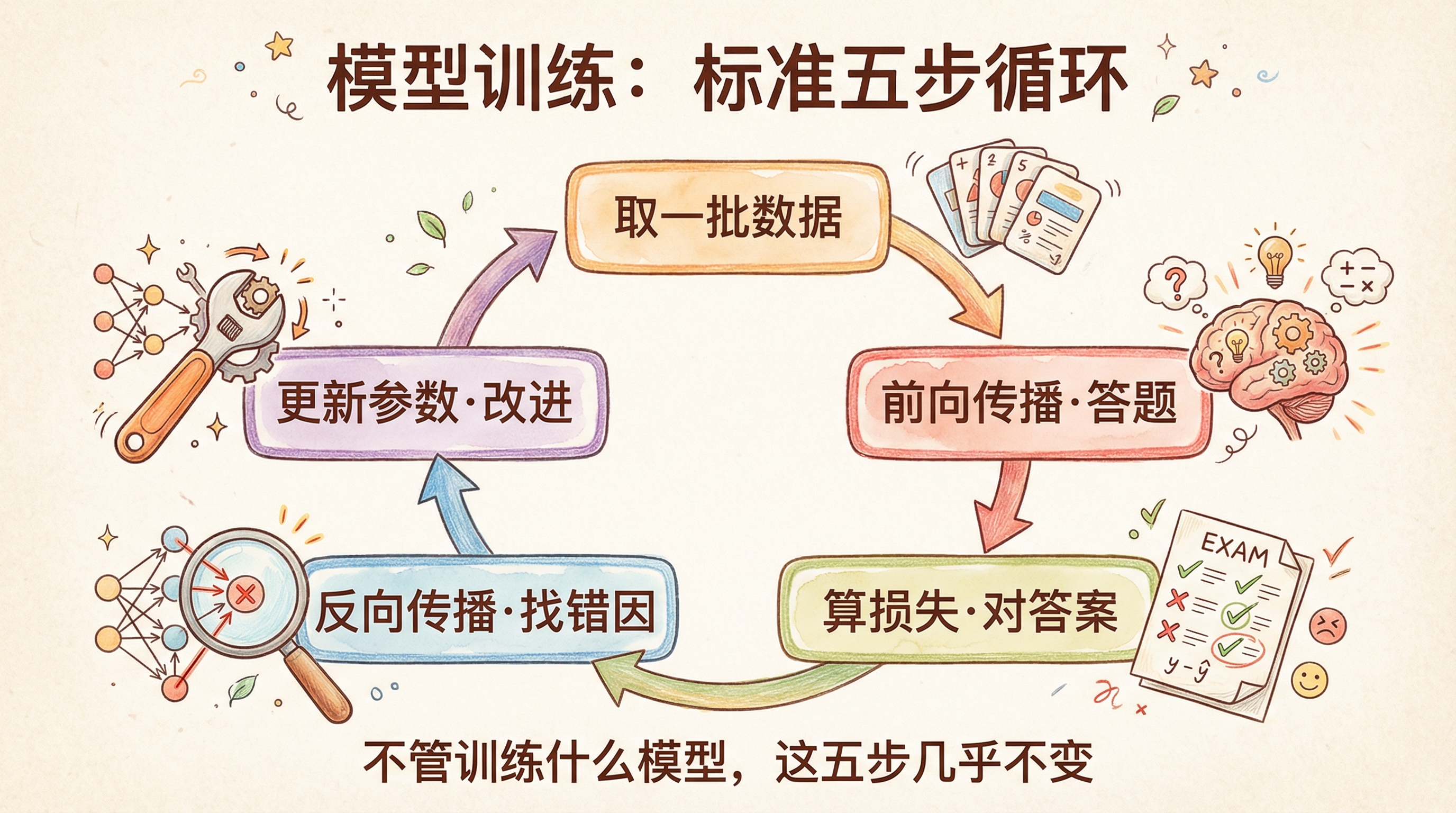
几乎所有深度学习项目的训练循环都长这样:
for epoch in range(5): # 把所有数据学5遍
for data, target in train_loader: # 每次取一批数据
optimizer.zero_grad() # 清空上次的梯度
output = model(data) # 前向传播:模型答题
loss = criterion(output, target) # 算损失:对比答案,错了多少
loss.backward() # 反向传播:找出哪些参数导致答错
optimizer.step() # 更新参数:调整参数让下次更准
这五行代码是标准模板,不管训练什么模型几乎一字不变。区别只在于外面的 model、data、criterion 怎么定义。
其中:
optimizer(优化器):决定怎么更新参数,Adam 是最常用的criterion(损失函数):衡量预测和正确答案的差距,分类任务一般用 CrossEntropyLosslr=0.001(学习率):每次调整参数的步幅,太大学飘,太小学不动
训练结果
🚀 开始训练...
第 1/5 轮 | 损失: 0.2743 | 训练准确率: 91.9%
第 2/5 轮 | 损失: 0.1137 | 训练准确率: 96.5%
第 3/5 轮 | 损失: 0.0796 | 训练准确率: 97.6%
第 4/5 轮 | 损失: 0.0625 | 训练准确率: 98.1%
第 5/5 轮 | 损失: 0.0492 | 训练准确率: 98.4%
🧪 测试模型...
测试准确率: 97.6%
💾 模型已保存到 model.pth
可以看到准确率从 91.9% 提升到 98.4%。但训练轮次不是越多越好,训练太多轮会出现过拟合——模型把训练数据的噪声都"背"下来了,遇到新数据反而不准。就像对测试用例做了太多特殊处理,测试全过了但上线就出 bug。
训练产出的 model.pth 就是我们的 AI 模型文件,里面是模型学到的所有参数权重。
关于"效果好不好"
不只是看训练准确率。测试准确率更重要,它衡量模型在没见过的数据上的表现(泛化能力)。到了大模型领域更复杂,需要从准确性、流畅度、幻觉率、推理能力等多个维度评估,各家发布模型时贴的 benchmark 跑分就是这个意思。
训练好的模型跑在哪?
这是一个重要的认知:训练框架 ≠ 推理环境。
训练确实需要跑在 PyTorch/TensorFlow 上,但推理(模型上线使用)有很多选择:
| 推理引擎 | 适用场景 | 类比 |
|---|---|---|
| vLLM | 大语言模型推理 | Nginx / Tomcat |
| NVIDIA Triton | 企业级多模型管理 | K8s |
| llama.cpp | 个人 / 边缘设备 | 嵌入式轻量运行时 |
| ONNX Runtime | 跨平台通用 | JVM |
| TensorFlow Lite | 移动端 | 移动端运行时 |
现在如果听到某家公司说"自己部署了大模型",大概率后面跑的就是 vLLM。
为什么需要 GPU?
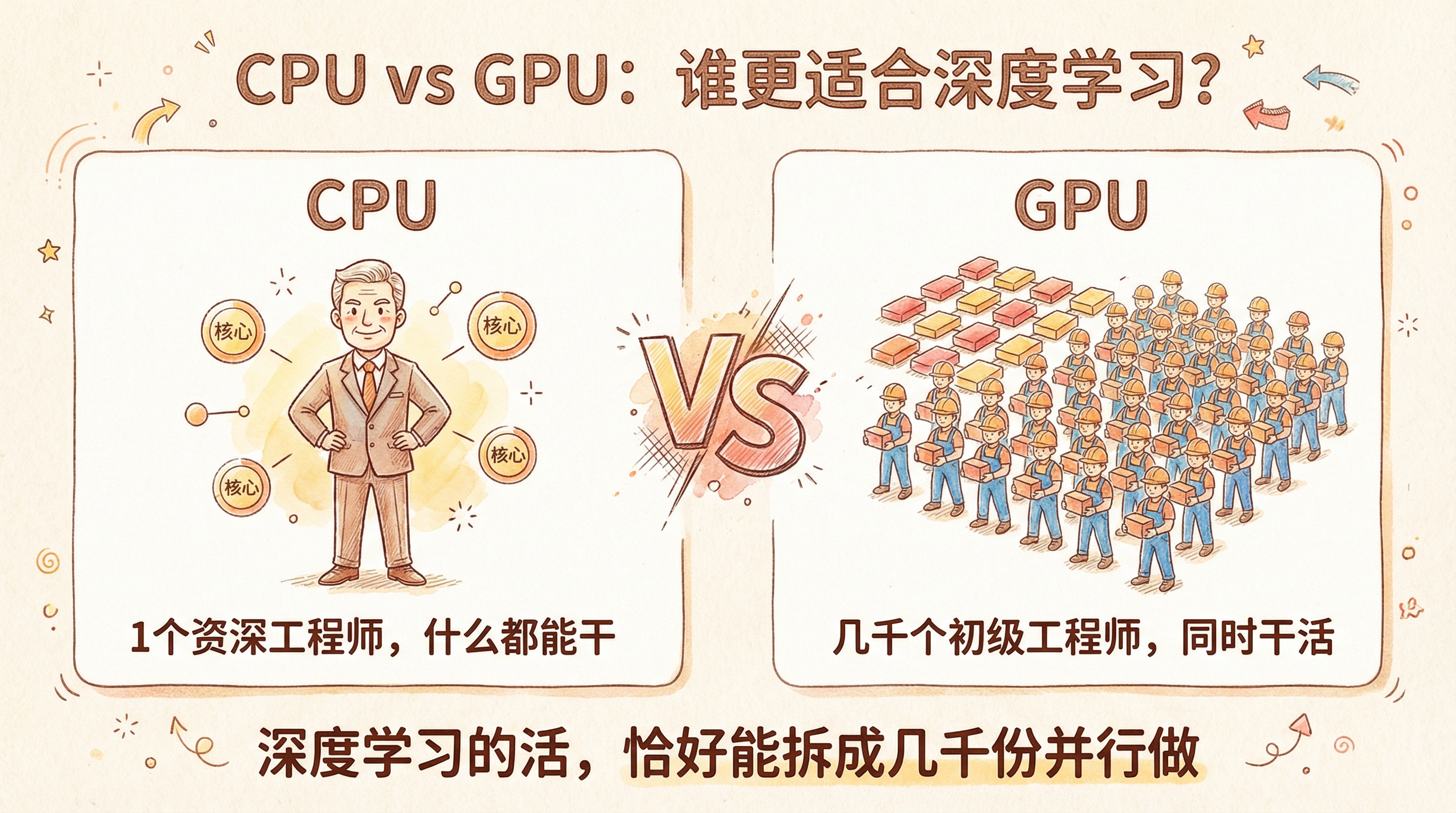
两个核心需求:算得快 + 放得下。
深度学习的本质是大量矩阵乘法,矩阵乘法天然可以拆成成千上万个互不依赖的小计算同时做。CPU 有几十个核心,GPU 有几千到上万个核心,虽然每个核心简单,但并行能力碾压 CPU。
类比:CPU 像一个资深工程师,什么都能干但只有一个人。GPU 像几千个初级工程师,每人只会简单运算,但可以同时干活。深度学习的活恰好就是把任务拆成几千份并行做。
GPU 有自己的显存(VRAM),模型必须加载到显存里 GPU 才能直接访问。大模型动不动几十上百 GB,一张 GPU 放不下就需要多张,这就是"模型并行"。
CUDA 和 NVIDIA 的护城河
CUDA 是 NVIDIA 的 GPU 编程框架,让 GPU 能做通用计算。PyTorch 底层调用 CUDA 来驱动 GPU。CUDA 经营了十几年,整个 AI 工具链都建在上面,这就是 NVIDIA 的护城河——不光硬件好,软件生态不可替代。
DGX Spark:桌面级 AI 超级计算机
NVIDIA 2025 年推出的 DGX Spark 是一台 Mac Mini 大小的 AI 专用电脑,128GB 统一内存(CPU/GPU 共享),售价约 $3,999,能在本地跑 200B 参数以内的模型。
有趣的是,苹果的 Mac Studio 用的也是统一内存架构,思路一样。区别在于 DGX Spark 原生支持 CUDA,AI 生态支持更好;Mac 更通用但 AI 优化不如 NVIDIA。
微调(Fine-tuning)
什么是微调?
拿一个已经训练好的模型,用你自己的少量数据再训练几轮,让它适应特定场景。
类比:预训练 ≈ 从零开发一个框架,投入巨大。微调 ≈ 拿成熟框架做二次开发,改配置加业务代码,快速适配需求。
为什么微调有效?
大模型在预训练阶段已经学会了语言能力和通用知识。微调不是让它学新技能,而是调整它的注意力和表达习惯。就像一个全栈工程师来你们公司干了三个月,底层能力没变,但他熟悉了你们的代码规范和业务术语。
微调不是炼丹,它的目标很清楚:用专业数据让模型在某个方向更准。只要数据质量好、量够,效果基本是确定性的。
动手微调
我们在手写数字识别模型的基础上,微调它来识别 26 个英文字母。核心思路:复用底层"怎么看笔迹"的能力,只重新训练输出层。
关键代码:
# 1. 加载旧模型,提取底层参数
old_model = OldSimpleNet()
old_model.load_state_dict(torch.load('model.pth'))
# 2. 创建新模型(26类),复用底层参数
model = NewSimpleNet(num_classes=26)
model.layers.load_state_dict(old_layers_params)
# 3. 冻结底层,只训练输出层
for param in model.layers.parameters():
param.requires_grad = False
requires_grad = False 就是告诉 PyTorch 这些参数锁住不要动。类比 fork 了一个开源项目,核心模块设成 read-only,只在新加的模块里写代码。
微调结果
用 5000 张数据,只训练 1,690 个参数(总参数 11 万),1.1 秒训练完成:
测试准确率: 49.2%
26 个字母随机猜是 3.8%,用这么少的数据和参数达到 49.2% 说明微调确实有效——底层复用的"看笔迹"能力起了作用。准确率不高是因为我们故意限制了数据量和可训练参数,用全量数据或解冻更多层效果会好很多。
蒸馏(Distillation)
什么是蒸馏?
用大模型教小模型。关键在于小模型学的不是标准答案,而是大模型的思考方式。
一张潦草的手写 3:
- 标准答案(硬标签):这是 3
- 大模型输出(软标签):3 的概率 70%,8 的概率 15%,5 的概率 10%
软标签里包含了"暗知识"——3 和 8 长得像、3 和 5 也有点像。小模型学这个概率分布,不光学到"这是 3",还学到了数据之间的关联关系。
类比:硬标签 ≈ 给你一份接口文档,只有输入输出。软标签 ≈ 资深工程师坐在旁边,不光告诉你答案,还告诉你"这里容易和那个混淆"。
蒸馏怎么做?
两种方式:
- 用大模型给现有数据打软标签,然后用软标签训练小模型
- 让大模型直接生成数据(问答对、推理过程等),拿生成的内容训练小模型
DeepSeek-R1 用的就是第二种——让大模型生成大量带思考过程的回答,蒸馏出的小模型也学会了"先思考再回答"。
蒸馏的成本优势
从零训练顶级大模型可能要几亿美元。蒸馏的话,大模型已有(别人训练好的),花推理费用生成高质量数据(可能几十万美元),再训练小模型,总成本是从零训练的百分之一,效果能达到大模型的 80-90%。
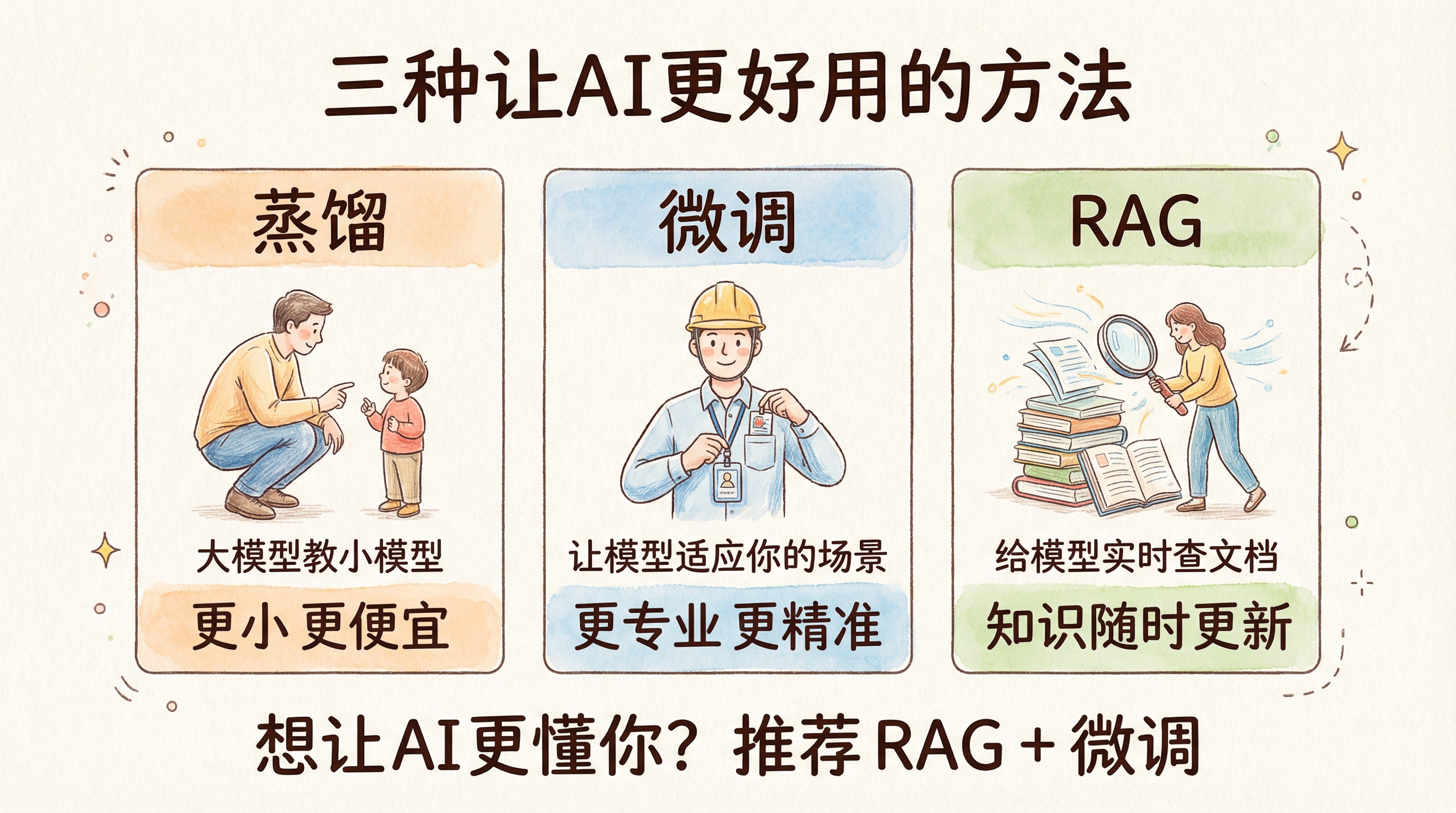
蒸馏 vs 微调 vs RAG
| 方法 | 目的 | 类比 |
|---|---|---|
| 蒸馏 | 得到更小更便宜的模型 | 培训一批初中级工程师替代资深团队 |
| 微调 | 让模型适应特定领域 | 让资深工程师熟悉你们的项目 |
| RAG | 给模型实时的外部知识 | 给工程师随时查文档的权限 |
如果你想让 AI 更懂你们的代码风格,最佳方案通常是 RAG + 微调,而不是蒸馏。
训练 AI 模型的工作量分布
最后总结一下训练 AI 模型的主要工作:
- 数据准备(60-70%):收集、清洗、标注数据。就像数据库设计和数据治理往往比写业务代码更耗时
- 模型架构设计:选什么类型的网络、多少层、每层多大。靠经验和实验
- 超参数调优:学习率、批量大小、训练轮次等。这些不是模型自己学的,是人手动设的
- 训练和评估的反复迭代:跑一轮看效果,不好就调整,再跑。可能重复几十上百次
入门不难,核心训练模板就那几行代码。难在数据工程、模型设计的直觉、调参、数学基础、以及大规模训练的工程挑战。就像写 CRUD 不难,但设计高并发分布式系统很难。
完整代码
本文涉及的所有代码(训练、预测、微调)都可以在 Mac 上直接运行,总共几十行,几分钟跑完。这可能是你能找到的最简单的深度学习入门实践了。