我解剖了这只爆火的龙虾
- 它究竟是什么?
- 整体架构:八层结构
- 第一层:入口——六种方式操控同一个 Agent
- 第二层:消息渠道——用 Baileys 协议搞定 WhatsApp
- 第三层:Gateway——整个系统的心脏
- 第四层:Hooks 与 Cron——自动化引擎
- 第五层:Agent 执行——本地 Coding Agent
- 第六层:LLM Provider 与浏览器——模型管理 + 自动化
- 第七层:记忆与技能——知识库 + 插件生态
- 第八层:基础设施——安全和配置的地基
- 结语:没有黑魔法
最近 OpenClaw(前身 Clawdbot)火遍硅谷到北京,有人说它是"AI 助手的终局形态"。两个月内斩获 14 万+ GitHub Stars,一堆人专门买 Mac Mini 跑它,二手价格都被炒起来了。
但它到底是怎么做到的?我把整个仓库 clone 下来,结合 AI 辅助,读了一遍源码——4700+ 个 TypeScript 文件,38MB,800+ 个 agent 相关模块。这篇文章是我的源码拆解笔记,你可以跟着我一起从技术视角搞清楚它的内部结构。
先说结论:其实没那么玄。
这是系列文章的第一篇,专讲架构。第二篇我们动手,用现有开源工具搭一个简易版 OpenClaw。
它究竟是什么?
用一句话描述:OpenClaw 是一个跑在你本地机器上的、以消息 App 为操控界面的持久化 AI Agent。
它不是聊天机器人,不是 Zapier 那样的自动化平台,也不是套壳 AI。核心差异就三点:
- 本地运行:数据不上云,你的代码、文件、记忆全在本机
- 持久化:24 小时在线,有 cron 定时任务,会主动工作
- 消息 App 为界面:你用 WhatsApp / Telegram / Discord / iMessage 跟它聊,它在后台对着你的电脑干活
整体架构:八层结构
读完代码,我把它的架构抽象成八层:
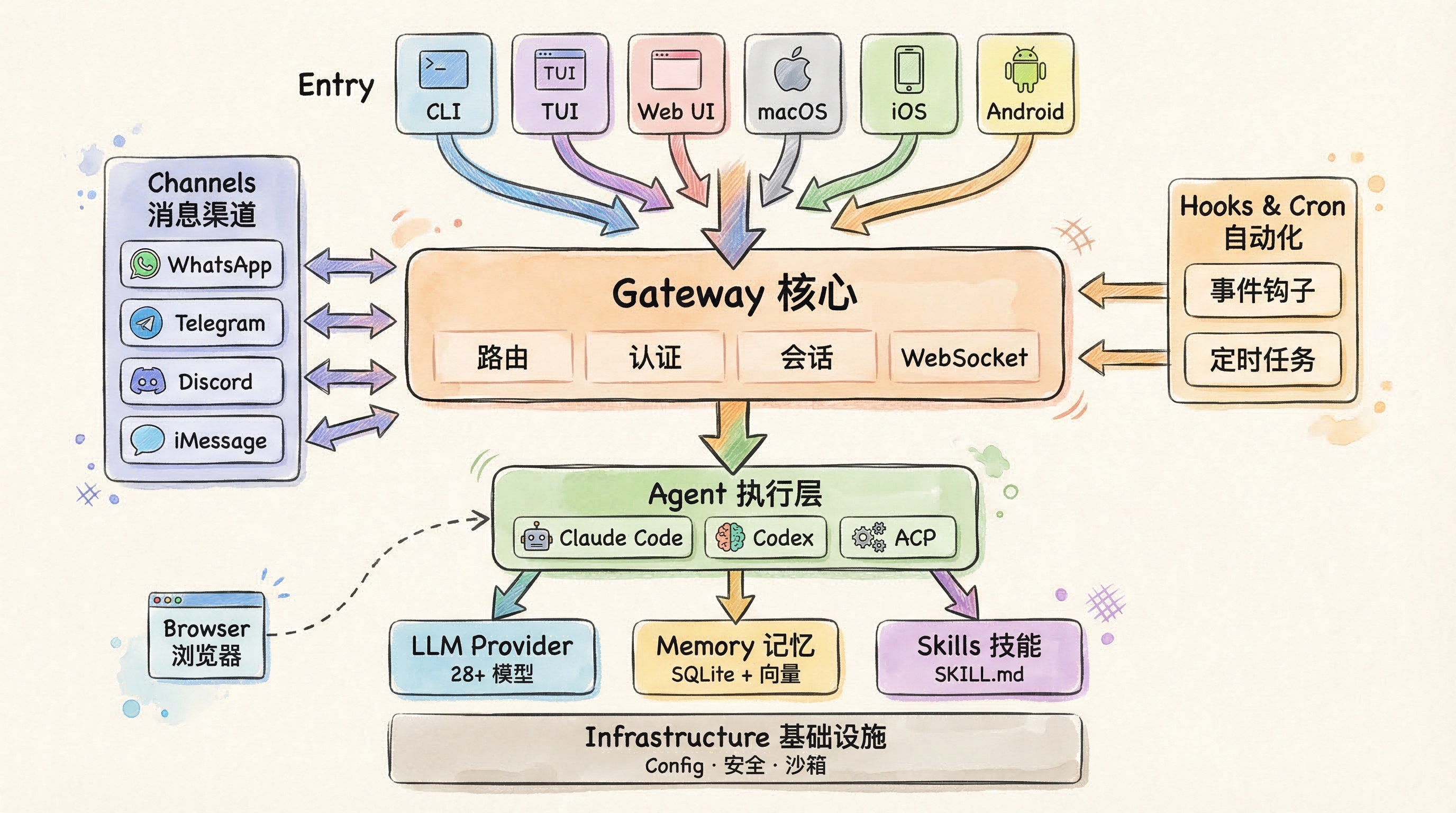
下面从上到下逐层拆解。
第一层:入口——六种方式操控同一个 Agent
最顶层是用户入口,OpenClaw 提供了多种交互方式,全部连到同一个 Gateway:
- CLI(
src/cli/):168+ 个命令文件,涵盖 agent 管理、浏览器调试、设备配对、cron 任务、插件管理等 - TUI(
src/tui/):基于pi-tui的终端交互界面,支持!前缀进 shell 模式、/前缀触发命令 - Web UI(
ui/):独立的 Vite + React SPA,通过 REST/WebSocket 连接 Gateway - macOS App(
apps/macos/):SwiftUI 菜单栏应用,内嵌 WKWebView 渲染 Canvas - iOS App(
apps/ios/):SwiftUI 原生应用,集成日历、摄像头、通讯录、位置等系统服务 - Android App(
apps/android/):Kotlin 原生应用
移动端和桌面端通过 Bonjour/DNS-SD 自动发现局域网内的 Gateway(服务类型 _openclaw-gw._tcp),TXT 记录里编码了 TLS 指纹和端口号。配对成功后,设备获得一个带作用域的 token,后续自动连接。
这种设计的精妙之处在于:你可以躺在沙发上用手机给 AI 下指令,它在书房的 Mac Mini 上执行。
第二层:消息渠道——用 Baileys 协议搞定 WhatsApp
很多人好奇:WhatsApp 并没有开放 API,OpenClaw 是怎么接入的?
答案藏在 src/web/ 目录。它用的是 @whiskeysockets/baileys,一个逆向工程了 WhatsApp Web 协议的开源库。
原理非常优雅——本质上就是模拟你电脑浏览器开着 WhatsApp Web:
手机 WhatsApp ←→ WhatsApp 服务器 ←→ 本地 Gateway(Baileys 长连接)
关键点:连接是从你本地主动发起的(出站),不需要公网 IP。WhatsApp 服务器会通过 WebSocket 长连接把消息实时推过来。就像你打开 WhatsApp Web 一样,只不过接收端是 OpenClaw 的 Gateway,而不是浏览器。
WhatsApp 的底层协议实现在 src/web/(登录、会话、收发消息),而 extensions/whatsapp/ 是基于 Plugin SDK 的封装层,负责把 WhatsApp 以标准渠道插件的形式接入系统。
渠道层的代码分布在 src/ 和 extensions/ 两层,每个渠道独立一个包:
src/
├── web/ ← WhatsApp Baileys 协议底层实现
├── telegram/ ← Telegram 核心逻辑
├── discord/ ← Discord 核心逻辑
├── slack/ ← Slack 核心逻辑
├── signal/ ← Signal 核心逻辑
├── imessage/ ← iMessage(仅 macOS)
└── line/ ← LINE 核心逻辑
extensions/
├── whatsapp/ ← WhatsApp 渠道插件封装
├── telegram/ ← Telegram Bot API 插件
├── discord/ ← Discord.js 插件
├── slack/ ← Slack Web API 插件
├── imessage/ ← AppleScript 插件(仅 macOS)
├── signal/ ← signal-cli 插件
├── feishu/ ← 飞书 Webhook
├── msteams/ ← Microsoft Teams
├── matrix/ ← Matrix 协议
├── googlechat/ ← Google Chat
├── irc/ ← IRC
├── bluebubbles/ ← BlueBubbles(另一种 iMessage 方案)
└── ...(还有更多)
这个两层设计值得注意:src/ 放协议级的底层实现,extensions/ 放标准化的插件封装。每个渠道实现一套统一的 ChannelPlugin 接口,包含:认证、收发消息、媒体处理、群组管理等能力。这个设计让 Gateway 完全不关心下层是什么 App,消息统一流入。
第三层:Gateway——整个系统的心脏
src/gateway/ 是整个项目最核心的目录。Gateway 是一个常驻后台的 WebSocket 服务(默认端口 18789),所有客户端(CLI、Web UI、macOS App、iOS、Android)都通过 WebSocket 连接到它。它同时也提供 HTTP 端点用于健康检查和控制面板。
先看它的内部结构:
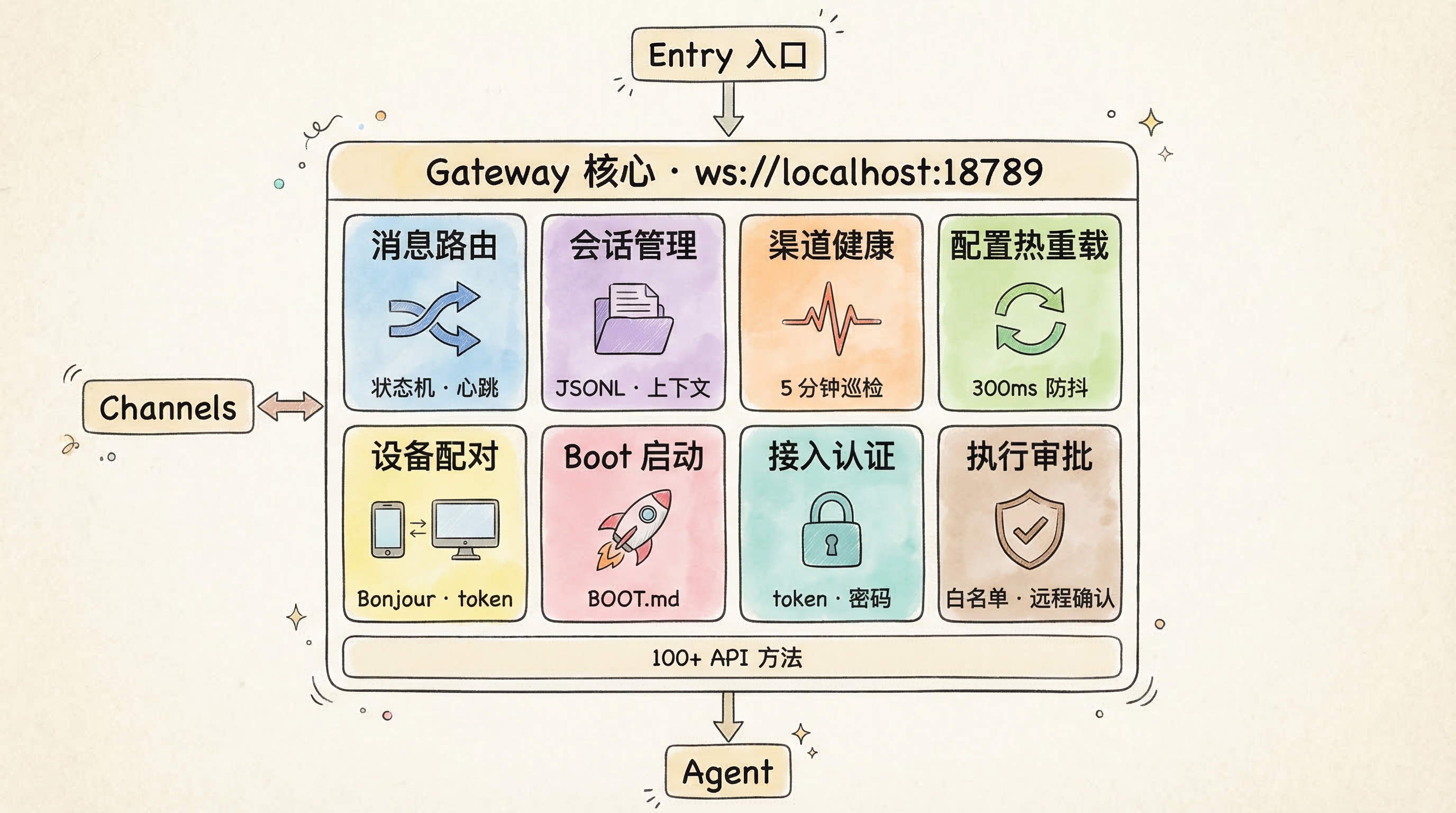
从 server-methods-list.ts 可以看到,Gateway 对外暴露了 100+ 个 WebSocket 方法,远不止"消息转发"这么简单。下面展开几个最关键的。
消息路由与状态机
收到消息后,Gateway 会根据发送人、群组、配置等判断:这条消息该不该响应?该交给哪个 Agent?
每个对话的执行状态由一个状态机管理(src/channels/run-state-machine.ts):
// src/channels/run-state-machine.ts
// 模块级常量:心跳间隔 60 秒
const DEFAULT_RUN_ACTIVITY_HEARTBEAT_MS = 60_000;
export function createRunStateMachine(params: RunStateMachineParams) {
let activeRuns = 0;
// 跟踪并发执行数、心跳、超时
// ...
}
状态机会跟踪每个对话的并发执行数,通过 60 秒一次的心跳向上游汇报"我还活着"。
会话管理
每个对话有独立的 session,以 JSONL 文件存储在本地文件系统(路径:~/.openclaw/agents/{agentId}/sessions/{sessionId}.jsonl)。每次 LLM 调用都会带上完整的历史上下文——OpenClaw 用文件系统实现了跨进程的持久化会话。
渠道健康监控
这是保证 7×24 稳定在线的关键(src/gateway/channel-health-monitor.ts)。
健康监控器每 5 分钟巡检一次所有已连接的渠道,检测"僵尸连接"——比如 Slack 的 WebSocket 看起来是活的,但实际上已经不推送消息了。它会根据最后一次收到事件的时间判断是否需要重启渠道连接。
安全措施:每小时最多 10 次自动重启,启动后有 60 秒宽限期,防止疯狂重连。
配置热重载
Gateway 用 chokidar(文件监听库)监控配置文件变化,300ms 防抖后自动重载(src/gateway/config-reload.ts)。
它会做配置 diff:逐字段对比新旧配置,只重新加载变化的部分。如果你改了 WhatsApp 的配置,它不会重启 Telegram 的连接。重载模式支持 hybrid(按需决定热重载还是全量重启)。
Boot 机制——用人话写的启动脚本
这是我觉得体现 OpenClaw 设计哲学的一个机制。(自然语言代替机器语言)
传统软件的启动脚本是 init.d、systemd、.bashrc——都是代码。而 OpenClaw 的启动脚本是一个 Markdown 文件,内容是自然语言。
用户在 Agent 的工作目录下创建一个 BOOT.md,写上人话:
每次启动后,给我的 WhatsApp 发一条"Gateway 已上线"。
然后检查一下今天的日历,如果有会议,提前提醒我。
Gateway 启动时,会遍历所有 Agent,读取各自工作目录下的 BOOT.md,把内容塞进 prompt 交给 Agent 执行:
// src/gateway/boot.ts
function buildBootPrompt(content: string) {
return [
"You are running a boot check. Follow BOOT.md instructions exactly.",
"",
"BOOT.md:",
content,
"",
"If BOOT.md asks you to send a message, use the message tool.",
// ...
].join("\n");
}
几个值得注意的设计选择:
- 用户手写,系统不生成。文件不存在就跳过,存在就执行——跟
.gitignore一个思路,约定文件名。 - 每个 Agent 独立一份。不是全局一个
BOOT.md,而是每个 Agent 工作目录下各自一个。monitor Agent 启动时检查服务状态,assistant Agent 启动时发问候语——各司其职。 - 临时会话,不污染历史。执行时生成
boot-{时间戳}-{随机ID}的临时 session,完成后恢复原始会话映射,回复用NO_REPLY令牌吞掉,不会出现在用户的对话记录里。 - 失败不阻塞。
BOOT.md执行失败只记 warn 日志然后continue到下一个 Agent,Gateway 照常启动。 - 它是一个Hook。Boot 机制实现在
src/hooks/bundled/boot-md/handler.ts,通过监听gateway-startup事件触发,是可插拔的——拿掉也不影响 Gateway 启动。
本质上,OpenClaw 把传统的 init.d 启动脚本降维成了自然语言,执行者从 shell 换成了 AI Agent。非程序员也能定义"AI 开机后该干什么",同时怎么折腾都不会把系统搞挂。
接入认证
注意:这里的认证是谁可以连接 Gateway,不是 LLM 模型的 API Key 管理(那是 Provider 层的事)。
Gateway 支持四种认证方式(src/gateway/auth.ts):
- none:无认证(仅限回环地址访问时)
- token:令牌认证
- password:密码认证
- trusted-proxy:信任代理(Tailscale 等)
还内置了速率限制(auth-rate-limit.ts),防止暴力破解。
执行审批
当 Agent 要执行危险命令时,Gateway 充当"门卫":
Agent 想执行 rm -rf /tmp/data
→ Gateway 拦截
→ 推送审批请求到你的 Telegram / WhatsApp
→ 你回复"允许"
→ Gateway 放行
审批请求通过 exec.approval.request 方法发出,通过 exec.approval.resolve 方法回收决策。这能让你来实现人在外面也能远程批准或拒绝 Agent 的操作。
第四层:Hooks 与 Cron——自动化引擎
这层包含两套互补的自动化机制:Hooks(事件驱动,"如果……就……")和 Cron(时间驱动,"每当……就……")。
Hooks 事件系统
Hooks 本质上是一个贯穿全系统的事件总线。src/hooks/internal-hooks.ts 定义了五大事件类型:
| 事件类型 | 触发时机 |
|---|---|
command |
用户发出命令时 |
session |
会话创建/销毁/切换时 |
agent |
Agent 启动/工具调用/回复生成时 |
gateway |
Gateway 启动/关闭/配置变更时 |
message |
收发消息、音频转写完成时 |
注册钩子时,可以监听整个类型(如所有 message 事件),也可以精确到 type:action(如 message:received)。触发时,系统会同时通知两层监听者。
一个关键设计:钩子异常不会阻断主流程。每个 handler 的错误被独立 catch 和日志记录,保证一个插件崩溃不会拖垮整个系统。
这套机制让你可以做到:消息进来时自动打标签、Agent 调用工具前先审批、Gateway 启动后自动发状态通知——全部通过声明式的事件订阅,不用改核心代码。
Cron 定时任务
src/cron/ 是实现"主动 AI"的关键。它底层用 croner 库,支持两种调度模式:
every:每隔 X 分钟/小时执行一次at:在特定时间执行一次
// src/cron/schedule.ts
export function computeNextRunAtMs(schedule: CronSchedule, nowMs: number): number | undefined {
if (schedule.kind === "at") {
// 处理精确时间调度
}
// 处理 cron 表达式(用 croner 库解析)
const cron = resolveCachedCron(expr, timezone);
你可以跟 OpenClaw 说"每天早上 8 点给我发今日新闻摘要",它会创建一个 cron job,时间到了自动执行,主动发消息给你。这就是它"不用你问,它主动找你"的实现原理。
Hooks 和 Cron 合在一起,覆盖了两种自动化场景:Hooks 响应系统内部事件(被动),Cron 按时间表主动触发(主动)。两者都通过 Gateway 调度,最终都是调用 Agent 来执行具体任务。
第五层:Agent 执行——本地 Coding Agent
这层是最有趣的部分。很多人以为 OpenClaw 自己实现了一个 AI Agent,但实际上——它调用的是外部的 Coding Agent CLI。
双引擎架构
看 src/agents/cli-backends.ts,OpenClaw 内置了两个 Agent 后端:
// 后端 1:Claude Code CLI
const DEFAULT_CLAUDE_BACKEND = {
command: "claude",
args: ["-p", "--output-format", "json",
"--permission-mode", "bypassPermissions"],
// ...
};
// 后端 2:Codex CLI
const DEFAULT_CODEX_BACKEND = {
command: "codex",
args: ["exec", "--json", "--sandbox", "workspace-write"],
// ...
};
默认使用 Anthropic 的 Claude Code(src/agents/defaults.ts 写死了 DEFAULT_PROVIDER = "anthropic",DEFAULT_MODEL = "claude-opus-4-6")。也可以切换到 OpenAI 的 Codex。
但这里有一个容易混淆的概念需要区分——"谁来执行"和"谁来思考"是两回事:
- CLI 后端(执行引擎):负责"怎么跑"——接收 prompt、spawn 进程、执行工具调用、管理 session。内置 Claude Code 和 Codex 两个,但代码里(第 243-250 行)留了扩展口:只要在配置里提供
command、args等字段,就能注册任意自定义后端。 - LLM Provider(思考引擎):负责"怎么想"——哪家的模型来生成回复。这个支持极其广泛。
从 models-config.providers.static.ts 里能看到硬编码的静态 Provider 就有一大堆:MiniMax、小米 Mimo、Moonshot/Kimi、通义千问、豆包(Doubao)、BytePlus、Together、OpenRouter、NVIDIA、千帆、Kilocode……再加上动态发现的 Ollama、HuggingFace、vLLM、Vercel AI Gateway,以及文档里记录的 Anthropic、OpenAI、Google Gemini、Mistral、Perplexity、AWS Bedrock、Azure 等——总计 28+ 个 Provider。
也就是说,你可以用 Claude Code 作为执行引擎,但让它背后调用通义千问或 Ollama 本地模型来"思考";也可以用 Codex 作为执行引擎,配上 Google Gemini 来生成回复。执行引擎和思考引擎是正交的。
那这么多 Provider,底层是怎么统一调用的?答案是一个叫 @mariozechner/pi-ai 的 SDK(版本 0.57.1)。它负责抹平不同 LLM API 之间的协议差异。从代码里看,28 个 Provider 最终只需要适配两种 API 协议:
| API 协议 | 使用的 Provider |
|---|---|
anthropic-messages |
Anthropic、MiniMax Portal、小米 Mimo、Kimi Coding |
openai-completions |
OpenAI、Moonshot、通义千问、豆包、OpenRouter、NVIDIA、千帆、Together、Kilocode… |
为什么大部分国产模型都走 openai-completions?因为 OpenAI 的 Chat Completions API 已经成了事实标准,几乎所有模型厂商都做了兼容。所以 OpenClaw 接入一个新模型,通常只需要配一个 baseUrl + API Key,不用写一行适配代码。
顺便说一句,OpenRouter 不是 OpenClaw 的路由框架——它只是 28 个 Provider 中的一个选项。OpenRouter 本身聚合了很多模型,所以配上它就等于一个 API Key 接入了几百个模型。但 OpenClaw 自己的 Provider 管理(Auth Profile 轮换、failover、模型发现)是独立实现的,不依赖 OpenRouter。
这两个后端都是本地运行的 Coding Agent——它们能读写文件、执行命令、调用 API。OpenClaw 的角色是"调度器":接收用户消息,拼装上下文,调用底层 CLI,拿到结果后发回给用户。
两层权限模型
这里有一个容易误解的设计。OpenClaw 默认给底层 CLI 传了 --permission-mode bypassPermissions,意思是 Claude Code 层面不做任何权限确认。这听起来很危险,但安全由 OpenClaw 自己的执行审批层兜底:
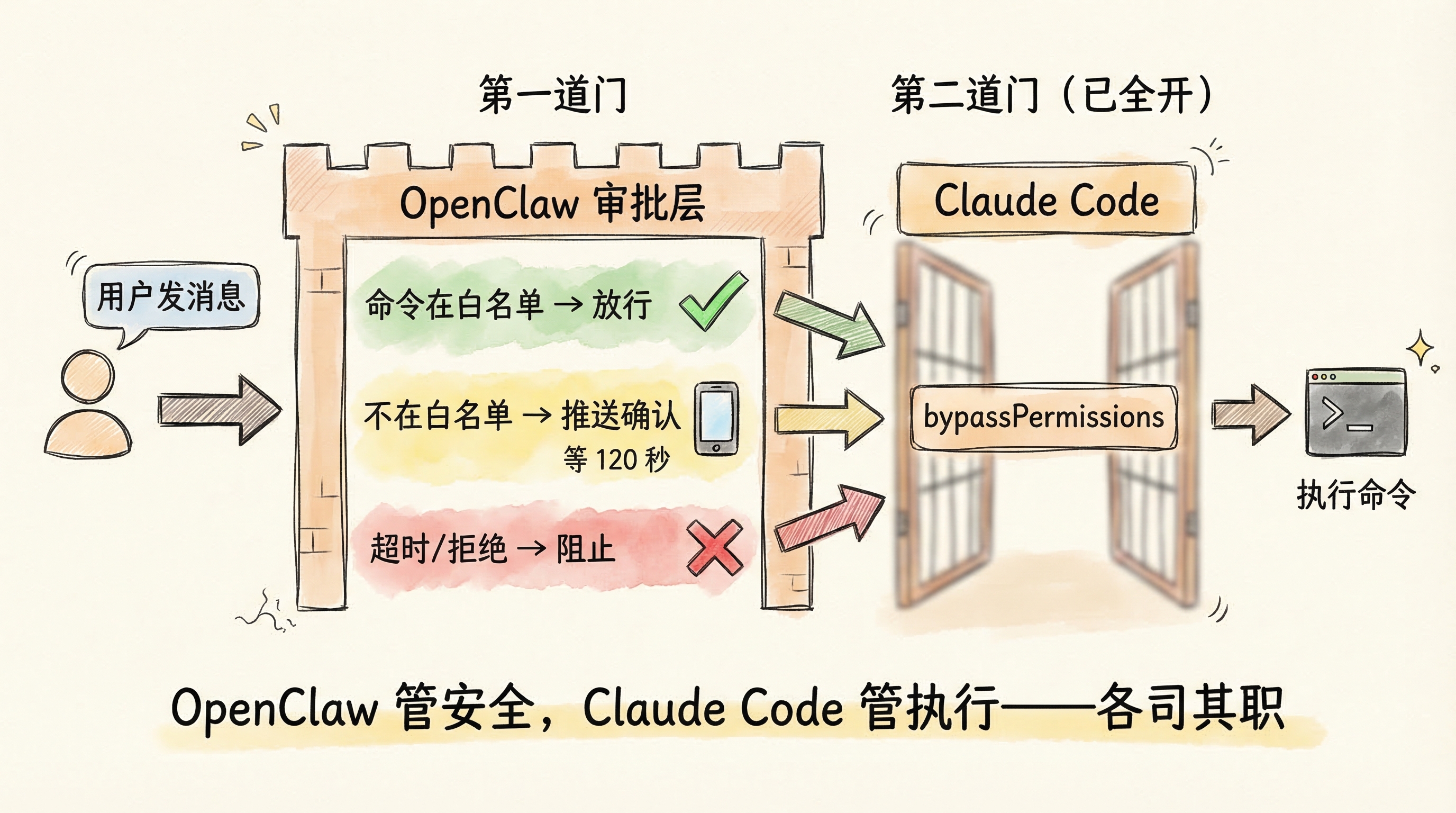
为什么这么设计?因为 OpenClaw 是 7×24 无人值守运行的,如果两层都要弹确认,用户一条命令要批两次。所以在自己的层面做好管控,到底层就全放行。
一次调用的完整流程
src/agents/cli-runner.ts 的 runCliAgent() 揭示了每次 Agent 调用的完整过程:
- 解析工作目录——每个 Agent 有独立的 workspace
- 加载 bootstrap 文件——类似 CLAUDE.md 的上下文注入,有 token 预算管理(防止 prompt 过长)
- 拼装 system prompt——追加心跳提示、额外指令
- 选择模型和认证——从 Auth Profile 轮换中选一个可用的 API Key
- 调用底层 CLI——spawn 子进程,JSON 格式通信
- 流式接收输出——支持边生成边推送给用户
- 处理失败——认证错误、限流、上下文溢出,各有不同的 failover 策略
另一条路:嵌入式运行
除了调外部 CLI,OpenClaw 还有一个嵌入式运行模式(src/agents/pi-embedded-runner/)——直接在进程内通过 pi-ai SDK 调用 LLM API,不经过外部 CLI。这条路径支持:
- Auth Profile 轮换(Key 挂了自动换下一个)
- 上下文窗口保护(
CONTEXT_WINDOW_HARD_MIN_TOKENS硬限制) - 会话压缩(
compactEmbeddedPiSession,对话太长时自动压缩历史) - 模型 failover(主模型挂了切备用模型)
ACP——多智能体协议
src/acp/ 目录(30 个文件)实现了 Agent Communication Protocol,这是 OpenClaw "多智能体"能力的底层基础。
它允许一个 Agent 孵化子 Agent,各自独立运行:
src/acp/server.ts— ACP 服务端,管理子 Agent 生命周期src/acp/client.ts— ACP 客户端,与父 Agent 通信src/acp/policy.ts— 权限策略,控制子 Agent 能做什么src/acp/translator.ts— 协议翻译,适配不同 LLM 的消息格式src/acp/persistent-bindings.ts— 持久化绑定,子 Agent 可以跨会话存活
比如你说"帮我同时查三个 API 的文档",主 Agent 可以 spawn 三个子 Agent 并行处理,各自独立工作,最后汇总结果。
第六层:LLM Provider 与浏览器——模型管理 + 自动化
这层提供 Agent 执行时依赖的两大外部能力:LLM 模型调用和浏览器自动化。
LLM Provider——28 个供应商,挂了就换
这是独立于 Agent 执行层的一整套 模型供应商管理体系。
src/agents/auth-profiles/ 实现了一个带自动轮换的认证档案系统。每个 Provider(如 OpenAI、Anthropic、Google Gemini、通义千问等)可以配多个 API Key(称为 Auth Profile),系统会自动 round-robin 轮换,并根据失败原因区分处理:
- 瞬时故障(限流、过载)→ 设置
cooldownUntil,冷却后自动重试 - 永久故障(欠费、Key 失效)→ 设置
disabledUntil+ 原因,需要人工介入
失败原因按严重程度分级:auth_permanent > billing > model_not_found > overloaded > rate_limit > unknown。
更有趣的是模型自动发现机制(src/agents/models-config.providers.discovery.ts):
- Ollama:调用本地
/api/tags获取已拉取模型列表,再逐个/api/show查询上下文窗口大小,8 个并发、5 秒超时 - HuggingFace / vLLM:走 OpenAI 兼容的
/v1/models端点 - Vercel AI Gateway / Kilocode:各有专用的发现逻辑
这意味着你本地跑了新的 Ollama 模型,OpenClaw 可以自动发现并使用,不用手动配置。
浏览器 & 媒体——让 AI 用你的浏览器
src/browser/ 有 135+ 个文件,实现了一个完整的浏览器自动化框架。底层基于 Playwright 和 Chrome DevTools Protocol (CDP)。
这不是简单的网页爬虫——它是一个有状态的浏览器会话管理器:
- PageState 跟踪每个页面的控制台消息(上限 500 条)、页面错误(200 条)、网络请求(500 条)
- 通过 角色快照(Role Snapshot)生成页面的无障碍树(Accessibility Tree),每个可交互元素分配稳定引用 ID
- 导航前做 SSRF 防护检查,禁止访问内网地址
src/media/ 则处理多媒体:解析 Agent 输出中的 MEDIA: <path> 标记,管理媒体文件的存储和生命周期(2 分钟 TTL 自动清理),检查音频格式兼容性(Telegram 语音消息只接受 ogg/opus/mpeg/m4a),文件大小限制 5MB。
第七层:记忆与技能——知识库 + 插件生态
这层让 Agent 拥有长期记忆和可扩展能力。
记忆系统——向量数据库 + SQLite + FTS
这是 OpenClaw 跟普通聊天机器人最本质的区别。记忆系统默认开启,用户不需要手动配置。
存储层:SQLite 一库多表
看 src/memory/memory-schema.ts,记忆系统建在本地 SQLite 上(路径:~/.openclaw/memory/{agentId}.sqlite),有五张核心表:
-- 1. 键值元数据
CREATE TABLE meta (key TEXT PRIMARY KEY, value TEXT NOT NULL);
-- 2. 源文件索引(跟踪哪些文件被记忆了)
CREATE TABLE files (
path TEXT PRIMARY KEY,
source TEXT DEFAULT 'memory', -- 来源:memory 目录 or sessions
hash TEXT NOT NULL, -- SHA256,用于判断内容是否变化
mtime INTEGER, size INTEGER
);
-- 3. 文本分块 + 向量嵌入
CREATE TABLE chunks (
id TEXT PRIMARY KEY, -- hash(path:startLine:endLine:hash:model)
path TEXT, source TEXT,
start_line INTEGER, end_line INTEGER, -- 在原文件中的行号范围
hash TEXT, model TEXT, -- 用哪个模型生成的嵌入
text TEXT, -- 分块原文
embedding TEXT NOT NULL, -- 向量,JSON 格式的 float 数组
updated_at INTEGER
);
-- 4. FTS5 全文检索虚拟表(只索引 text 列,其余为元数据)
CREATE VIRTUAL TABLE chunks_fts USING fts5(
text, id UNINDEXED, path UNINDEXED, source UNINDEXED, ...
);
-- 5. 二进制向量表(用于高效向量搜索)
-- embedding 以 Float32Array buffer 存储,避免 JSON 解析开销
写入:自动索引 + 智能分块
记忆系统会自动监听 memory/ 目录和 MEMORY.md 文件的变化(用文件 watcher,1500ms 防抖),变化后自动重新分块和嵌入。
分块策略(src/memory/internal.ts):
- 按 400 token(约 1600 字符)切分
- 相邻分块之间有 80 字符重叠,保证语义连贯
- 每个分块独立嵌入,生成一个向量
嵌入后端支持多种:
| 后端 | 默认维度 |
|---|---|
OpenAI text-embedding-3-small |
512 维(默认) |
OpenAI text-embedding-3-large |
3072 维 |
| Google Gemini | 768 维 |
| Voyage | 1024 维 |
| Mistral | 1024 维 |
| Ollama(本地) | 768 维 |
嵌入结果会缓存在 embedding_cache 表里——同一段文本不会重复计算嵌入,换模型时才重新算。
读取:混合检索
检索时不是只用向量搜索,而是混合检索(src/memory/manager.ts):
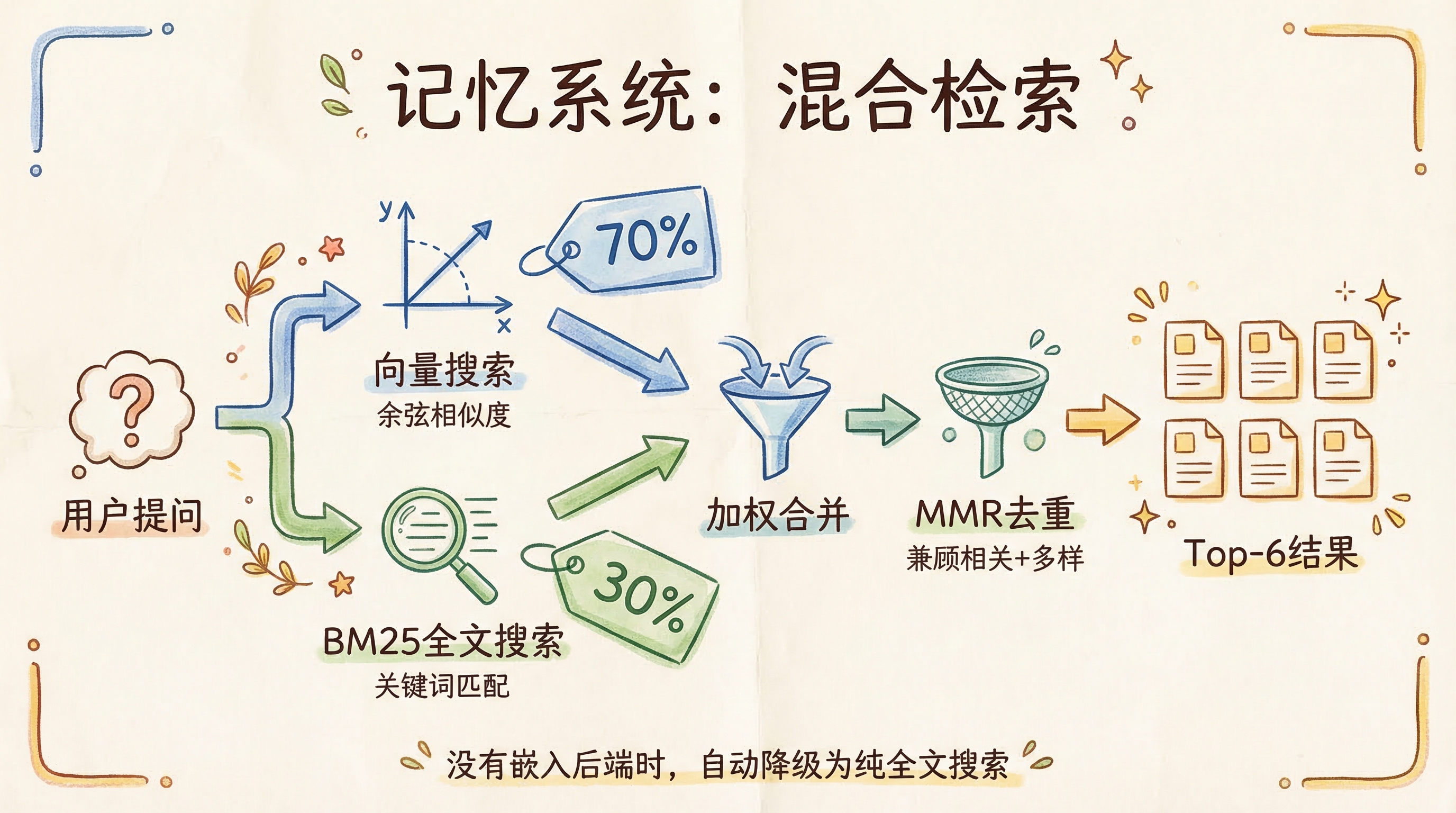
MMR(Maximal Marginal Relevance)算法在 src/memory/mmr.ts 里,用的是 Jaccard 相似度(词集交并比)来度量已选结果之间的重复度,公式:MMR = 0.7 × 相关性 - 0.3 × 与已选最大相似度。
如果没配嵌入后端(比如纯离线环境),系统会自动降级为纯 FTS 搜索——功能打折但不会挂。
Agent 怎么用记忆
记忆不是自动塞进 prompt 的——它通过两个工具调用实现:
memory_search:搜索记忆,返回匹配的文本片段和来源引用memory_get:读取记忆文件的指定行范围
Agent 的 system prompt 里有一条显式指令(src/agents/system-prompt.ts):
"Before answering anything about prior work, decisions, dates, people, preferences, or todos: run memory_search on MEMORY.md + memory/*.md; then use memory_get to pull only the needed lines."
也就是说,Agent 被教会了要先查记忆再回答——这不是硬编码的检索逻辑,而是通过 prompt 引导 Agent 自主决定何时、搜什么。
可选:LanceDB 向量后端
除了内置的 SQLite 方案,extensions/memory-lancedb/ 提供了一个可选的 LanceDB 后端(基于 Apache Arrow 的向量数据库)。它用 L2 距离做向量搜索,支持按类别(conversation / task / decision / context)组织记忆,适合对向量检索性能有更高要求的场景。
Skills 技能系统——插件市场
skills/ 目录和 extensions/ 目录是两套不同的扩展机制:
- Extensions:核心功能扩展,消息渠道、认证提供商等,随主程序一起发布
- Skills:轻量级技能包,社区发布,用户按需安装
一个 Skill 本质上就是一个 SKILL.md 文件——Markdown 格式,头部用 YAML frontmatter 声明元数据(名称、描述、依赖的工具、安装方式),正文用自然语言告诉 Agent 这个 Skill 怎么用、什么时候用:
skills/github/
└── SKILL.md ← YAML frontmatter(元数据)+ Markdown(使用说明)
举个例子,skills/github/SKILL.md 的 frontmatter 里声明了需要 gh CLI,并提供了 brew/apt 两种安装方式;正文则包含"什么场景该用 / 不该用"和常用命令模板。Agent 会根据这些信息自主决定何时调用、怎么调用。
没有单独的 tools.yaml——工具定义直接内嵌在 Markdown 里。这种设计的好处是一个文件就是一个完整的技能包,降低了社区贡献门槛。
社区的 ClawHub 上目前有超过 13,000 个社区技能。这是 OpenClaw 最大的护城河——生态。
第八层:基础设施——安全和配置的地基
最底层的 src/config/ 和 src/infra/(300+ 个文件)支撑着整个系统:
配置系统:支持 JSON5 格式(允许注释和尾逗号),密钥引用(Secret Refs)可以指向环境变量、文件或命令输出,在配置导出时自动替换为占位符,防止明文泄露。
执行安全:src/infra/exec-approvals.ts 维护一个动态的命令白名单,支持 safe-bin(安全二进制)、custom-allowlist(自定义白名单)、always-ask(总是询问)三种策略。每条命令执行前还会通过 detectObfuscation() 检测是否有混淆注入。
路径沙箱:boundary-path.ts 确保文件操作不会逃逸出配置的沙箱根目录;archive-path.ts 防止 zip-slip 攻击;hardlink-guards.ts 通过检查 inode 数防止硬链接攻击。
结语:没有黑魔法
读完这八层,回到开头的结论:其实没那么玄。
OpenClaw 的每一层都不是从零发明的——Baileys 是现成的,Playwright 是现成的,SQLite + FTS5 是现成的,Claude Code / Codex 是现成的。它真正做的事情是把这些东西粘成一个 7×24 在线的、多渠道的、有记忆的 Agent 系统,然后在每一层都留下扩展口。
如果要用一句话总结它的设计哲学:用自然语言代替机器语言。BOOT.md 是自然语言的启动脚本,SKILL.md 是自然语言的插件包,记忆系统是自然语言的数据库查询。这不是"套壳"——这是一种新的系统设计范式,把 AI 当成操作系统的一等公民。
下一篇,我们不光看,还要动手——用现有的开源工具,搭一个简易版的 OpenClaw。