不卷模型,开始卷 Harness 了
- 别再卷模型了,套在外面的 Harness 才是胜负手
别再卷模型了,套在外面的 Harness 才是胜负手
Humans steer, agents execute. 人类掌舵,智能体执行。

一个重新理解 AI 工程的发现
2025 年大家都在证明一件事:AI Agent 能写代码。到了 2026 年,一个更有意思的事实——Agent 写得好不好,跟模型本身的关系没那么大,跟模型外面那层"壳"的关系才大。
LangChain 的人在 Terminal Bench 2.0 上做了个实验:同一个模型(GPT-5.2-Codex),一行代码没改,只动了模型周围的系统设计——提示词怎么组织、工具怎么调用、中间件怎么插。结果得分从 52.8% 飙到 66.5%,排名从 Top 30 开外直接杀进 Top 5。
OpenAI 自己的 Codex 团队更猛。一个小团队 5 个月时间,用 Agent 生成了超过 100 万行代码——零行手写。不是玩具项目,是可以跑的东西:应用逻辑、文档、CI 配置、可观测性、内部工具,全是 Agent 干的。工程师全程在干嘛呢?在设计让 Agent 能可靠干活的那套系统。
Vercel 他们的数据团队把 Agent 能用的工具从 15 个砍到 2 个——对,你没看错,砍掉了 80%。结果成功率从 80% 跳到 100%,速度快了 3.5 倍,token 还省了 37%。
三个故事都在讲述一个道理:决定 Agent 干活质量的,不是模型多聪明,是你给它搭的环境多靠谱。这个环境,行业里现在叫它 Harness。围绕 Harness 做工程,就是所谓的 Harness Engineering。
先说清楚:从提示词到 Harness,我们到底经历了什么
2022-2024:提示词工程
最早大家就是在琢磨怎么"问个好问题"。Chain-of-thought、few-shot、角色扮演……花了两年研究怎么在一个文本框里写出完美指令。有用,但说白了就是一句话的事——你写一段,它回一段。
2025:上下文工程
2025 年 Andrej Karpathy 给了个更精准的说法:上下文工程就是"往上下文窗口里精确地塞对的信息"。他打了个比方——LLM 是 CPU,上下文窗口是 RAM。提示词工程是在 RAM 里写指令,上下文工程是决定 RAM 里该放什么。
这个阶段大家意识到:模型能不能干好活,很大程度取决于它"看到"了什么。同一个模型,上下文给得不一样,输出天差地别。到 2025 年底,"Context Engineer"这个头衔开始正经出现在招聘里了。
2026:Harness Engineering
但光管"给模型看什么"还不够。当 Agent 不再是一问一答,而是要连续跑五十一百次工具调用、跨十几个文件改代码、自己做架构决策——你还得管它的行为边界、验它的输出、清理它搞出来的烂摊子。
Epsilla 有个特别直觉的比喻:
- 提示词工程 = 写一封完美的邮件
- 上下文工程 = 把该附的文件都附上
- 驾驭工程 = 设计整套办公基础设施——工位、流程、权限、审批、质检
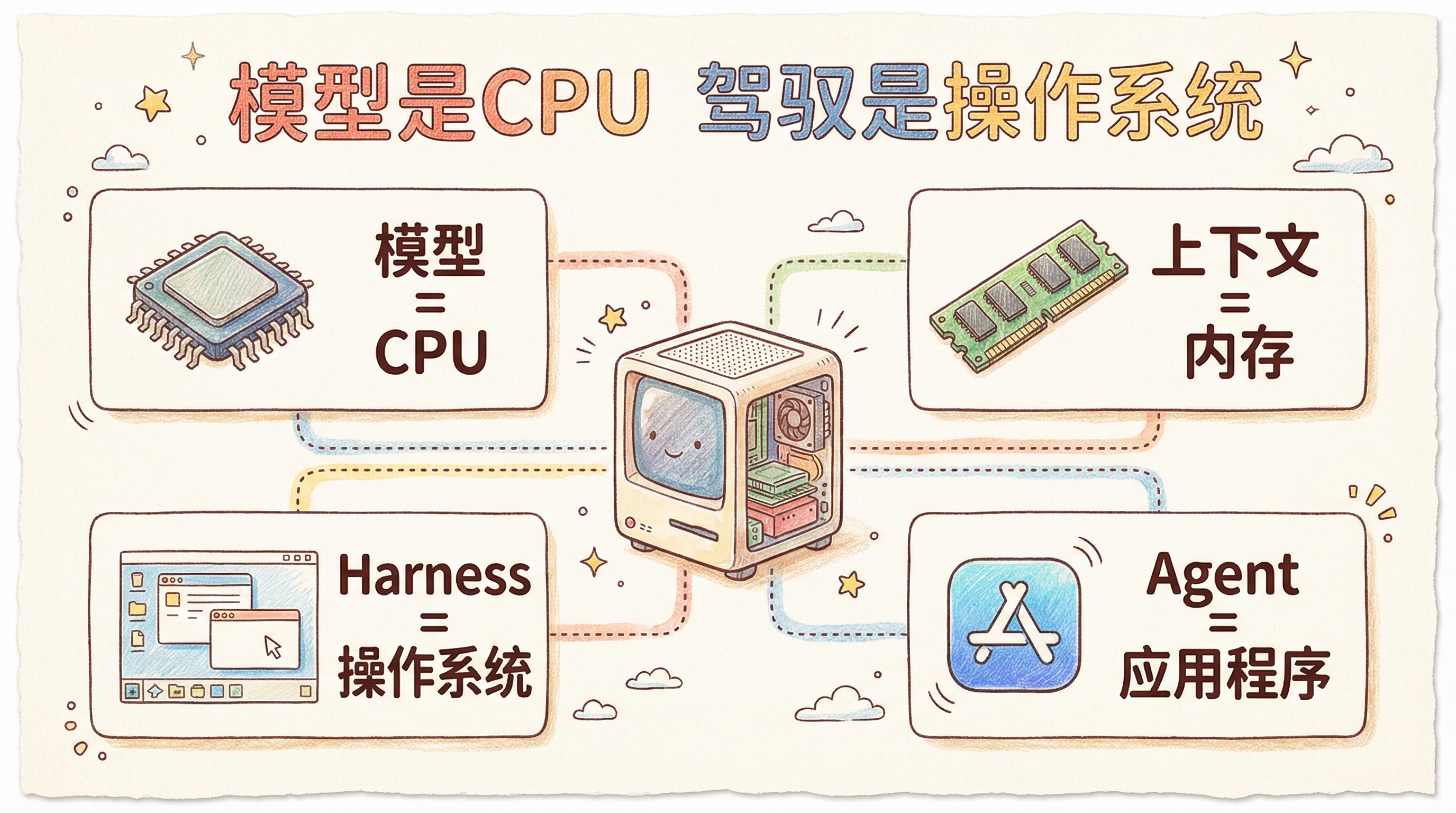
Philipp Schmid 的比喻更极客一点:Model 是 CPU,Context Window 是 RAM,Harness 是操作系统,Agent 是应用程序。这一下就说清楚了——Harness 不是模型本身,也不是上层应用,是让一切跑起来的那个操作系统层。
所以 Harness 到底是啥?
Harness 这词来自马具——套在马身上的缰绳和鞍具。不是让马跑更快,而是把马的力量引到你想去的方向。
放到 AI 这边:模型是引擎,Harness 是整辆车。
具体一点,一个好的 Harness 干四件事:
- 约束——Agent 能干啥不能干啥(架构边界、依赖规则、文件权限)
- 告知——Agent 该干啥(上下文、文档、代码规范)
- 验证——Agent 干对没有(测试、linter、CI)
- 纠正——干错了怎么修(反馈回路、自修复机制)
有人会问:这跟 SDK、框架有啥区别?SDK 和框架解决的是"怎么构建 Agent",Harness 解决的是"Agent 怎么跑"。Claude Code、Codex CLI、LangChain DeepAgents 这些东西,本身就是 Harness 的实现——它们提供了 prompt 预设、工具调用的默认处理、生命周期钩子、子 Agent 管理这些现成能力。
其实 Harness 比模型更重要
LangChain:模型没换,排名从 30 开外冲进 Top 5
同一个 GPT-5.2-Codex,只改 harness:
| 指标 | 改之前 | 改之后 |
|---|---|---|
| Terminal Bench 2.0 | 52.8% | 66.5% |
| 排名 | Top 30 开外 | Top 5 |
他们做了三件事:加了个 Self-Verification Loop(提交前强制自测),写了个 Loop Detection(检测 Agent 在同一个文件上反复改来改去的死循环),优化了启动时的上下文注入。
有意思的是他们发现了个叫"Reasoning Sandwich"的技巧:不让模型全程开最高推理(那样会超时,只有 53.9%),而是规划阶段用最高推理、写码阶段用中等、验证阶段再拉回最高。跟人脑一个道理——想方案时深思熟虑,写代码时进入心流,review 时再切回审慎模式。这一招直接拿到 66.5%。
Vercel:砍掉 80% 的工具,成功率反而到了 100%
原来有 15 个工具(schema lookup、query validation、error recovery 之类的),团队后来发现自己是在"替模型思考"——帮它过滤信息、帮它规划路径。结果砍到只剩 bash 和 SQL 两个工具:
| 指标 | 15 个工具 | 2 个工具 |
|---|---|---|
| 成功率 | 80% | 100% |
| 执行时间 | 274.8 秒 | 77.4 秒 |
| Token | ~102k | ~61k |
| 步骤数 | ~12 | ~7 |
最夸张的对比:旧系统最差情况跑了 724 秒、烧了 14.5 万 token 还失败了;新系统干同一个查询只用 141 秒、6.7 万 token,成功。
他们总结了一句特别到位的话:"当我们不再替模型做选择时,模型反而做出了更好的选择。"
不过有个前提——他们的语义层文档写得很好。他们自己也说了:如果你的数据层一团糟,给 Claude 直接文件访问也救不了你。
Nate B Jones:同一个模型,差的 harness 42%,好的 78%
差距接近一倍。Harness 带来的影响是模型原始能力的两倍。
OpenAI:5 个月,100 万行代码,零行手写
一个小团队,全程 depth-first——把大目标拆成小积木块,让 Agent 搭积木,再用积木解锁更复杂的东西。他们最后说了句让我印象很深的话:
"我们最大的挑战不在于模型的能力,而在于设计环境、反馈回路和控制系统。严谨的工程设计并没有因为 AI 而变得简单——它变得更重要了。"

有这么一个道理:约束越多,Agent 反而表现越好
我们总觉得给 AI 更多自由它就能发挥得更好。但实际上限制了解空间,Agent 才能在有限范围内找到正确答案,而不是在无穷可能性里迷路。就像 TypeScript 比 JavaScript 多了一堆"限制",但正是这些限制让你写出更靠谱的代码。
HumanLayer 的 Kyle 说得更直白:Agent 出问题时,第一反应别想着等更强的模型,先检查你的配置。这不是模型问题,是配置问题。
就像高速公路上有护栏你反而敢开快,Agent 在好的约束下反而能更自主——因为 harness 替它兜底了。
Harness的三大支柱
OpenAI 的实践加上 Birgitta Böckeler 在 Martin Fowler 博客上的分析,Harness 可以拆成三根柱子。

第一根柱子:上下文工程——Agent 看不到的东西等于不存在
你团队的 Google Docs、Slack 里的默契、大家脑子里那些"这个大家都知道"的东西——Agent 统统看不到。它能看到的只有仓库里的文件和运行时能拿到的信息。
所以核心就一句话:一切知识必须编码到仓库中。
静态上下文就是 Agent 的"入职文档":
项目根目录/
├── AGENTS.md # Agent 行为指南
├── CLAUDE.md # Claude Code 专用指南
├── ARCHITECTURE.md # 架构决策记录
├── docs/
│ ├── api-design.md
│ ├── patterns.md
│ └── decisions/
AGENTS.md 是 2026 年冒出来的一个好东西——面向 AI Agent 的 README,Claude Code、Cursor、Codex 都认。HumanLayer 建议控制在 60 行以内。为啥?上下文窗口是有限资源,塞太多模型反而会迷失。
这些文件该告诉 Agent 什么?技术栈和版本、代码风格的硬规则(不是"写得优雅",是"函数不超过 50 行")、哪些模式推荐哪些禁止、测试怎么跑、提交规范是啥。
动态上下文是运行时感知:监控数据、CI 状态、目录结构映射。LangChain 的 LocalContextMiddleware 会在启动时自动扫描项目结构和可用工具注入进去,这个挺聪明的。
还有个重要理念叫渐进式披露——别在启动时把所有信息一股脑塞给 Agent,让信息随着任务推进按需浮现。MCP Servers、Skills、Sub-Agents 都是做这个的。
有条反直觉的原则值得记住:成功应该是沉默的,只有失败才需要产出。早期有人跑完整测试套件,5 分钟的通过结果全丢给 Agent,那些无关信息反而淹没了真正需要关注的失败用例。
还有一点——写得好的代码本身就是最好的文档。清晰的命名、一致的模式、合理的抽象,比注释更能帮 Agent 理解你的意图。Böckeler 甚至预测:未来开发会趋向更少的、对 AI 更友好的技术栈——不是为了人类偏好,是为了 Agent 好维护。
第二根柱子:架构约束——别跟 Agent 讲道理,直接拦住它
团队里的代码规范如果靠人自觉都经常破防,Agent 就更不会自觉了。必须把约束变成可执行的检查。
约束分四层:
第一层:确定性 Linter(ESLint、checkstyle、golangci-lint)
第二层:结构化测试(ArchUnit——Service 层不能直接调 Repository)
第三层:自定义 Linter(禁止在 Controller 层写业务逻辑)
第四层:LLM 审计 Agent(用 AI 审查 AI 的输出)
最简单有效的是 pre-commit hooks。Agent 提交代码时 hook 自动跑,不通过就不让提交。Agent 不需要"理解"规则,被规则拦住就行了。
HumanLayer 管这叫 Back-Pressure——测试、类型检查、linter 形成一种反压力,让 Agent 犯错后能"感知"到错误并自我修正。这比让 Agent 自己评估靠谱多了——Anthropic 的研究表明模型自评时过于宽容,很容易说服自己 bug 不严重。
Loop Detection 也很关键。LangChain 发现 Agent 经常在同一个文件上改了又改,每次改一点每次还失败,陷入死循环。他们的解法很简单:追踪每个文件编辑次数,超过 N 次就中断,提示 Agent 换个思路。简单但管用。
Sub-Agents 做任务隔离也很重要。Agent 跑久了会出现"上下文腐化"——上下文越来越长,性能越来越差。Sub-Agent 就是一道防火墙,子任务的中间噪音不会污染主 Agent 的上下文。
举个真实例子:OpenAI 发现 Agent 老喜欢把所有逻辑塞一个函数里。他们没去"教育"Agent,直接写了个 linter——函数超过 50 行就报错。结果 Agent 学会了拆函数。不是因为它理解了为什么要拆,是因为不拆过不了检查。
第三根柱子:熵管理——AI 生成的代码天然趋向混乱
OpenAI 团队以前每周五花 20% 时间清理"AI 垃圾"——重复代码、不一致的命名、偏离模式的实现。太痛苦了。后来他们想通了:把"黄金规则"编码到仓库里,然后用专门的 Agent 定期巡检。
Böckeler 在 Martin Fowler 博客上专门强调了这一点,引用了 OpenAI 的原则:"When the agent struggles, we treat it as a signal"——Agent 挣扎的地方,就是 harness 需要加强的地方。
垃圾回收 Agent 干的事很直接:查文档跟代码是否一致、找偏离约定模式的代码、识别冗余实现、检查依赖是否过时。可以定时跑、PR 合并后跑、或者发现问题后针对性扫。
Philipp Schmid 还指出了一个新问题叫 Agent Drift——模型跑久了会慢慢偏离指令,像车慢慢跑偏一样。排行榜上 1% 的差距根本测不出来这种东西。所以 Harness 不光要在开始前设好规则,还要全程持续监测纠偏。
有个重要的反馈循环:垃圾回收 Agent 反复发现同一类问题时,说明你的约束不够。这时候该回到第二根柱子去补规则,别每次手动修。
超姐 OpenAI Codex,Harness 长什么样
OpenAI 把 Codex 的内部架构细节公开了,可以看看一个生产级 Harness 的真实面貌。
核心其实是一个特别简单的循环:
1. 接收输入,构造 prompt
2. 模型生成响应——要么是最终回答,要么是工具调用
3. 如果是工具调用,执行它,把结果追加回 prompt
4. 回到第 2 步,直到模型不再调用工具
就这么简单。但围绕这个循环搭的 Harness,才是真正的工程量。
Codex 跑在 CLI、VS Code、Web、macOS 桌面、JetBrains、Xcode 这些界面上,底下统一由一个 Codex App Server 驱动——基于 JSON-RPC 的双向 API。它抽象了三个核心概念:
- Item——输入输出的原子单位(消息、工具执行、审批请求、diff)
- Turn——一次完整的 Agent 工作序列
- Thread——持久化的会话容器,支持恢复、分叉、归档
还有个审批机制:Agent 要执行有风险的操作时,Server 会暂停并向客户端发审批请求,人点了"允许"才继续。自动化的同时人类始终有最终控制权。
再看看 Shopify:CEO 亲自上阵用 Agent 优化核心系统
Shopify CEO Tobi Lütke 2025 年发了份内部备忘录——"AI 使用是所有人的基线期望",要加人先证明 AI 干不了这活。八个月后 Box、Fiverr 甚至加拿大总理都跟进了。
但 Lütke 不只是发备忘录,他自己上手做了个示范。
他用了 Karpathy 的 Autoresearch 方法——让 coding agent 半自主跑大量实验,对 Shopify 的核心模板引擎 Liquid 做性能优化。写了个 autoresearch.md 提示文件加配套脚本,让 Agent 自动跑测试报 benchmark。跑了大概 120 次实验,产出 93 次提交:
- parse+render 快了 53%
- 内存分配少了 61%
最大的单项优化是用 String#byteindex 替代正则 tokenizer,单独贡献了 12% 的解析提速。
这不是玩具。Liquid 驱动着 Shopify 560 万活跃店铺的前端渲染。CEO 亲自用 AI 对核心基础设施做出了有意义的改进——但关键不在于他用了多牛的模型,而在于他搭了一个严格的实验框架:有明确的 benchmark、自动化的测试运行器、结构化的结果收集。这就是一个轻量但有效的 harness。
怎么开始搞?从简单到复杂可以定义三个级别
Level 1:个人开发者
✅ 项目根目录放个 CLAUDE.md / AGENTS.md(控制在 60 行以内)
✅ 配好 pre-commit hooks(lint + type check + 测试)
✅ 写好测试套件
✅ 保持仓库整洁、命名一致
最低配的 harness,但已经能明显提升 Agent 输出质量。CLAUDE.md 长这样就够了:
# CLAUDE.md
## 技术栈
- Java 21 + Spring Boot 3.3
- PostgreSQL + MyBatis-Plus
- Gradle 构建
## 代码规范
- Service 层方法必须有单元测试
- Controller 层只做参数校验和响应包装,不写业务逻辑
- 所有数据库查询走 Repository 层
- 函数不超过 50 行
## 测试命令
./gradlew test
## 禁止事项
- 不要用 lombok 的 @Data,用 @Getter @Setter
- 不要在 Service 层直接拼 SQL
- 不要 catch Exception,必须 catch 具体异常类型
Level 2:小团队
Level 1 基础上加:
✅ 团队统一的 AGENTS.md(版本化管理)
✅ CI 里集成架构约束检查(ArchUnit 之类的)
✅ 共享的代码模式模板
✅ PR 审查加上 Agent 输出质量检查
✅ Loop detection(防止 Agent 在同一问题上原地打转)
Level 3:组织级别
Level 2 基础上加:
✅ 自定义中间件(拦截和约束 Agent 行为)
✅ 可观测性集成(监控 Agent 效果、检测 Agent Drift)
✅ 仪表盘(追踪成功率、Token 消耗、执行时间)
✅ 垃圾回收 Agent 定期巡检
✅ Harness 模板库(不同项目用不同模板)
✅ Agent 运行轨迹采集
最后一点 Philipp Schmid 特别强调了它的战略价值:竞争优势正在从 prompt 转向"捕获的运行轨迹"。Agent 每次在长工作流中跑偏,都是一条有价值的训练数据。
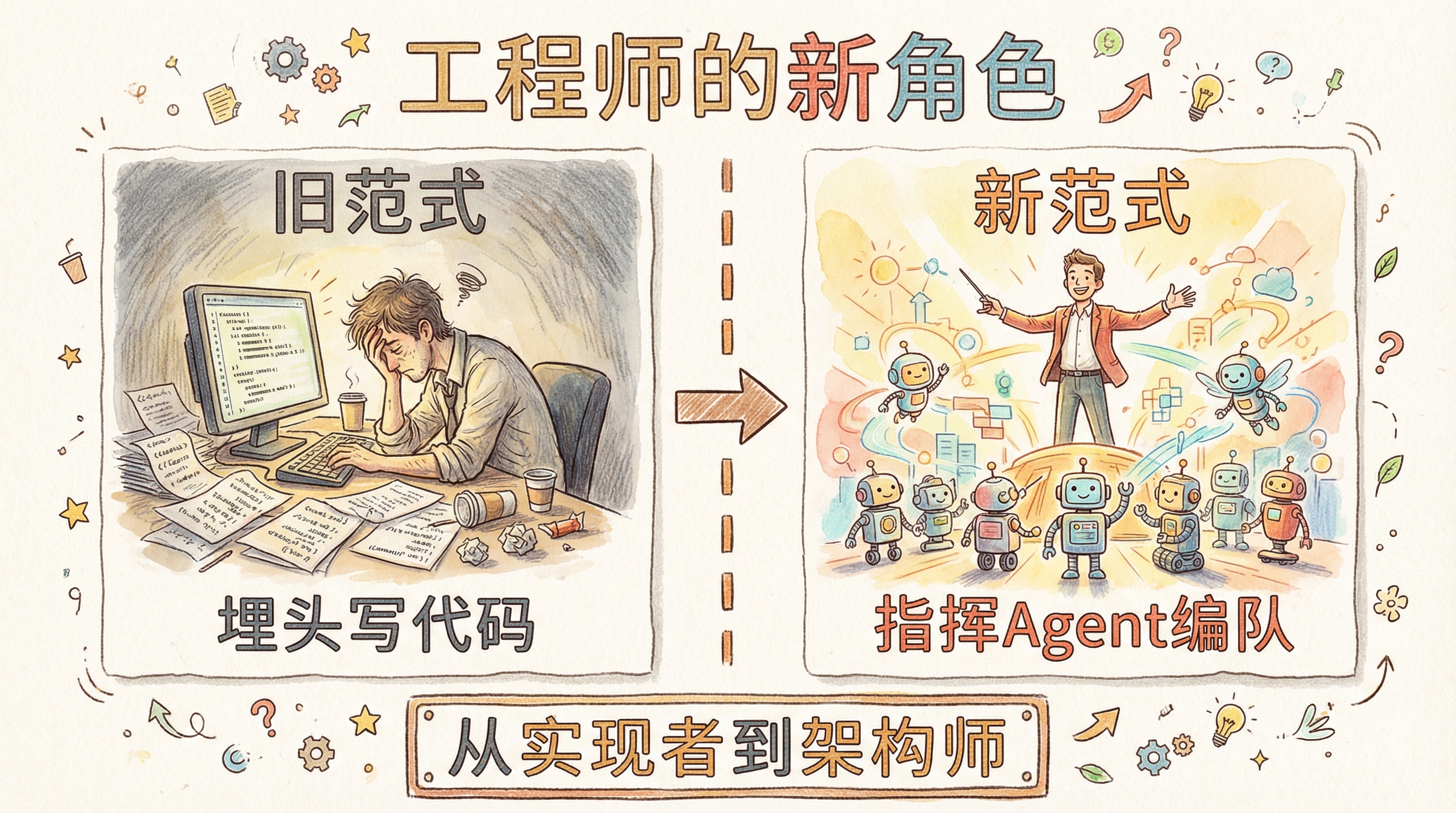
在这个时代里,代码工程师干的活变了
| 以前 | 现在 |
|---|---|
| 手写代码 | 设计约束和验证规则 |
| Debug 代码 | 分析 Agent 行为模式 |
| 写文档给人看 | 写文档给 Agent 看 |
| 学新语言新框架 | 设计 Agent 能理解的架构 |
| 代码审查 | Harness 审查 |
| 管团队协作 | 管 Agent 编排 |
这不是说不用会写代码了——恰恰相反,你需要更深的架构能力和系统思维才能设计好 harness。Karpathy 说 2026 年是 Agentic Engineering 时代,人类不再写大部分代码,而是指挥、监督、编排 Agent。就像交响乐指挥不亲自演奏每件乐器,但整场演出的质量由他决定。
换句话说:工程师不再直接解决问题,工程师解决的是 Agent 在解决问题时遇到的问题。你的交付物不是代码,而是一个让 Agent 持续可靠产出代码的系统。
下面是可能要踩的坑
过度设计控制流。 给 Agent 搞了个巨复杂的状态机,结果模型一升级全废了。Manus 6 个月重构了 5 次 harness,LangChain 一年重架构了 3 次。正解是 Philipp Schmid 说的"Build to Delete"——设计时就预期会被替换,保持模块化,给强的原子工具让模型自己规划。
写了 AGENTS.md 就再也不更新。 Harness 是活的,Agent 每次犯错都问一句:这个错误能用什么约束预防?然后把答案编码进去。
文档太模糊。 "代码要写得优雅" "注意性能"——这种话 Agent 理解不了。"函数不超过 50 行"比"函数要简短"好一万倍。
Agent 写了烂代码,人肉修完拉倒。 不去想为什么。OpenAI 的原则说得好:Agent 挣扎的地方就是 harness 需要加强的地方。每次犯错都是改进的机会。
知识留在仓库外面。 架构决策记在 Confluence,规范写在 Notion 里。Agent 只能看到仓库,一切知识必须在仓库内。
一次性塞太多上下文。 CLAUDE.md 写了几百行,测试输出全丢给 Agent。上下文是有限资源,让信息按需加载。聚焦 20 分钟的 session 胜过漫无边际的 2 小时。
让 Agent 自己评价自己。 Anthropic 研究表明模型自评时太宽容,容易说服自己 bug 不严重。必须用确定性的外部工具(测试、linter)做验证。要用 LLM 审查就得用独立的、配了严格标准的评估 Agent。
Harness 也不是万能的
只对能验证的任务管用。 代码能跑、测试能过、类型能检查——这些 harness 很擅长。但产品设计决策、用户体验判断、创意工作?缺确定性验证手段的场景,harness 能帮多少还是个问号。
功能正确性有缺口。 Böckeler 分析 OpenAI 的实践时指出:他们的内部质量指标都过了(风格一致、架构合规),但没验证"代码做的是不是对的事"。Agent 可能完美遵守所有规则,写出风格一致测试通过的代码,但它理解的需求跟产品团队想要的是两回事。
现在的 harness 还挺脆弱。 大部分是 linter 规则、CI 脚本和自定义 hook 拼出来的,换个模型版本或 Agent 工具可能就得大面积改。这个领域还没有出现类似 Kubernetes 之于容器编排那样的标准化层。
组织层面才是真正的挑战。 2026 年 Deer Valley 研讨会有份报告说得很直接:技术再好,如果团队没有维护 harness 的意愿和能力,它很快就会过时。
更大的上下文窗口不等于更好。 信息多了不代表模型更擅长从中找到有用的。塞太多反而让模型更难聚焦,这也是为什么按需加载比一次性全给更有效。
最后
一句话总结:别再只想着让 AI 更聪明了,让它的运行环境更聪明。
2025 年我们卷的是"哪个模型更强",2026 年我们发现真正的竞争力在于谁的 harness 更好。排行榜上模型差距越来越小,但真实场景里的表现差距越来越大——差距全在 harness 里。
三根柱子:
上下文工程 → 让 Agent 看到该看的
架构约束 → 让 Agent 不做不该做的
熵管理 → 让系统不会越跑越烂
三个数据:
- LangChain 同模型提升 26%,杀进 Top 5
- Vercel 砍 80% 工具,成功率从 80% 到 100%
- 好 harness 比差 harness 高出近一倍
这不是锦上添花,这是 AI Agent 时代写软件的基本功。
OpenAI 那句话我反复读了好几遍,拿来收尾刚好:
"严谨的工程设计并没有因为 AI 而变得简单——它变得更重要了。"
参考资料:
- OpenAI, "Harness engineering: leveraging Codex in an agent-first world", 2026
- OpenAI, "Unlocking the Codex harness: how we built the App Server", 2026
- OpenAI, "Unrolling the Codex agent loop", 2026
- Birgitta Böckeler (Martin Fowler's blog), "Harness Engineering", Feb 2026
- LangChain, "Improving Deep Agents with Harness Engineering", 2026
- Vercel, "We removed 80% of our agent's tools", 2026
- Philipp Schmid, "The importance of Agent Harness in 2026"
- HumanLayer, "Skill Issue: Harness Engineering for Coding Agents"
- Epsilla, "The Third Evolution: Why Harness Engineering Replaced Prompting in 2026"
- Andrej Karpathy on Context Engineering
- Shopify/liquid PR #2056: Performance: 53% faster parse+render
- Nate B Jones, Agent Harness benchmark research, Mar 2026
- Anthropic, "Demystifying evals for AI agents", 2026