我造了一只自己的龙虾
- 如果要自己实现OpenClaw,没必要都做
- Agent 执行层这个最重的活,我把它抽成了框架
- 当我实现 Gateway 的时候,有三个值得讲的坑
- 其余的常规模块的实现,就很简单了
- 让CodyClaw跑起来,然后体验下我们自研的小龙虾
- 有了Cody,那我自己到底实现了多少
- 最后说两句

上一篇我解剖了 OpenClaw,拆出了它的八层架构,末尾说:下一篇动手造一只。
这篇就是兑现承诺。我真的造了一只出来——叫 CodyClaw,跑在飞书上,效果还不错。
如果你也想自己动手造一只 Agent,这篇可以帮你少走一些弯路。下面讲三件事:砍什么留什么、造的过程中踩了哪些坑、最后跑起来是什么样。
如果要自己实现OpenClaw,没必要都做
先回顾一下上一篇拆出的八层架构。这张表值得花一分钟看看——它能帮你判断,如果自己动手造,哪些值得做、哪些该果断砍掉:

| 层 | OpenClaw 做了什么 | 我要不要做 |
|---|---|---|
| 一、入口层 | CLI、TUI、Web UI、macOS App、iOS、Android | 不做。飞书就是我的入口 |
| 二、消息渠道层 | WhatsApp(逆向协议)、Telegram、Discord、Slack 等 10+ | 只做飞书。官方 SDK,WebSocket 长连接 |
| 三、Gateway 层 | 消息路由、会话管理、状态机、健康监控、Boot 机制、执行审批 | 完整实现。这是心脏 |
| 四、Hooks & Cron 层 | 事件总线、cron 定时任务 | 做 cron,hooks 暂时不需要 |
| 五、Agent 执行层 | Claude Code CLI / Codex CLI,双引擎,嵌入式运行 | 完整实现——但抽成了独立框架 |
| 六、LLM Provider 层 | 28 个供应商、Auth Profile 轮换、模型自动发现 | 交给 Agent 框架处理 |
| 七、记忆与技能层 | 向量数据库 + FTS 混合检索、ClawHub 插件市场 | 简化版记忆,技能用 SKILL.md |
| 八、基础设施层 | 配置系统、执行安全、路径沙箱 | 基础的配置管理就够 |
数一下:两层完整实现(Gateway、Agent 执行),一层只做一半(Cron),两层大幅简化(记忆、Provider),三层不做(入口、多渠道、基础设施)。
真正绕不过去的就两件事:Gateway(消息怎么进来、怎么路由、怎么出去)和 Agent 执行(AI 怎么想、怎么调工具、怎么管上下文)。
先说最重的那个。
Agent 执行层这个最重的活,我把它抽成了框架

Agent 执行层是 OpenClaw 代码量最大的一层。它要干的事情包括:工具系统(文件读写、Shell、代码搜索……)、流式输出、会话上下文管理、权限控制、多模型适配。
我一开始试着自己写。写了两天发现不对——这些东西跟"龙虾"本身的业务逻辑完全无关。不管你是造龙虾还是造别的什么 Agent 应用,这些脏活都得干一遍。
所以我干了一件事:把这层抽出来,做成了一个独立框架 Cody。一句话说清楚它的定位:让你用几行代码就拿到一个带工具、带流式、带上下文管理、带MCP、Skill热加载机制的 Agent。它怎么设计的我后面会专门写一篇。
为什么要跟你说这个?因为如果你也想造自己的 Agent 应用,最大的建议就是:不要从零写执行层。不管用 Cody 还是 LangChain 还是别的什么,找一个趁手的框架把这层给承接了,把精力留给真正有跟你业务特性有关的部分——Gateway 和业务逻辑。
有了框架之后,CodyClaw 的 Agent 执行层就变成了这样:
client = AsyncCodyClient(
model="claude-sonnet-4-6",
api_key=config.api_key,
base_url=config.base_url,
skills_dirs=["./skills"],
tools=[*feishu_tools, *cron_tools],
)
async for chunk in client.stream("你把xxx活给我干了"):
if isinstance(chunk, TextDeltaChunk):
response += chunk.text
工具、流式、会话、上下文压缩、多模型——全在这个 client 里面。我只需要告诉它用什么模型、有哪些额外的自定义工具。
当我实现 Gateway 的时候,有三个值得讲的坑

Gateway 要做的事说起来简单:消息从飞书进来,路由到对应的 Agent,AI 处理完再把结果发回飞书。但真正写起来,有几个地方比想象中麻烦。
这三个坑我都踩过了,分享出来希望能帮你省点时间。
坑一:飞书 SDK 跟 asyncio 打架
飞书有官方 SDK lark-oapi,支持 WebSocket 长连接——连接从你的机器主动发出去,不需要公网 IP,接入本身很简单。
但它有个坑:SDK 在 import 的时候就把当前的 event loop 捕获到了模块级变量里。如果你的服务跑在 uvicorn 上,SDK 会抓到正在运行的 loop,然后调 loop.run_until_complete()——直接报 "this event loop is already running"。
解法有点 hack:在独立线程里建一个全新的 event loop,然后直接替换 SDK 模块里的 loop 变量。
def _run_ws_in_thread(self) -> None:
import lark_oapi.ws.client as ws_module
new_loop = asyncio.new_event_loop()
asyncio.set_event_loop(new_loop)
ws_module.loop = new_loop # 替换 SDK 模块级的 loop
self._ws_client = lark.ws.Client(...)
self._ws_client.start() # 阻塞在独立线程里,不影响 uvicorn
SDK 线程收到消息后,通过 asyncio.run_coroutine_threadsafe() 跳回 uvicorn 的主循环处理。两个世界就这么接上了。
这个解法不够优雅,飞书 SDK 升级后可能失效。如果你遇到同样的问题,先查一下 SDK 是否已经修复了这个 event loop 的问题,没修再用这个 hack。
坑二:AI 回复太慢,用户在干等
AI 生成一条回复可能要 10-30 秒。如果等它全部生成完再发,用户体验很差——你不知道它是在想还是挂了。
我的做法是流式卡片:先发一张"思考中"的蓝色卡片,然后随着 AI 一边生成一边更新卡片内容。
_CARD_UPDATE_INTERVAL = 1.5 # 再快会触发飞书 API 速率限制
async def _update_streaming_card(self, run, msg, force=False):
now = time.monotonic()
if not force and (now - run.last_card_update) < _CARD_UPDATE_INTERVAL:
return # 节流
content = run.accumulated_text.strip() or "⏳ 思考中..."
card = build_streaming_card("执行中", content, "running")
if run.card_message_id is None:
run.card_message_id = await self._channel.send_card(msg.chat_id, card)
else:
await self._channel.update_card(run.card_message_id, card)
1.5 秒这个数字是试出来的——飞书卡片更新的速率限制大约是每秒 5 次,但实测超过 1 秒一次就容易偶发 429,1.5 秒是个稳妥的值。完成后卡片变绿,附带 AI 调了哪些工具的列表。
还有个容易忽略的边界情况:如果 AI 通过工具自己给用户发了消息(比如调用 feishu_send_text),结束时就不应该再发一张卡片,否则用户会收到重复信息。所以收尾逻辑要分三种情况:有卡片就更新为完成态,没卡片但 AI 也没主动发消息就兜底发一张,AI 已经发过消息就什么都不做。
坑三:工具注册时,依赖还没初始化好
CodyClaw 要给 AI 注册自定义工具——比如发飞书消息、建定时任务。但有个时序问题:注册工具的时候,飞书 channel 可能还没连上,后续也可能断线重建。
如果你直接把 self._channel 传进去,工具拿到的是注册那一刻的实例——后面换了新实例,工具还在用旧的。
解法是闭包捕获 getter,而不是实例本身:
def make_feishu_tools(get_channel):
async def feishu_send_text(ctx, chat_id: str, text: str) -> str:
channel = get_channel() # 每次调用时取最新实例
if channel is None:
return "Error: Feishu channel is not available."
await channel.send_text(chat_id, text)
return "Message sent."
return [feishu_send_text, ...]
# 注册时传 lambda,不传实例
self._feishu_tools = make_feishu_tools(lambda: self._channel)
getter lambda 每次调用时拿活实例,组件之间完全解耦。这个模式在初始化顺序不确定的系统里非常好用——如果你做过依赖注入,会觉得很眼熟,本质上就是延迟绑定。
其余的常规模块的实现,就很简单了
除了上面三个坑,剩下的模块都是比较常规的工程实现。虽然不难,但有几个的实现细节值得展开聊聊。
消息路由
CodyClaw 支持同时跑多个 Agent——比如一个专门写代码,一个专门查资料。那问题来了:用户发了一条消息,该交给谁处理?
我的做法是按三级优先级匹配:
- 先看群:这个群有没有绑定过特定 Agent?比如"前端技术群"绑了代码 Agent,那群里所有消息都交给它。
- 再看人:如果群没绑定,看发消息的这个人有没有绑定?比如你把自己绑到了资料 Agent,那你的消息就走资料 Agent。
- 最后兜底:群没绑、人也没绑,走默认 Agent。
另外还有个触发条件:私聊机器人时每条消息都会触发,但在群聊里只有 @ 机器人才会触发——不然群里随便聊句天,AI 都要插嘴,太吵了。
实现就是几十行 if-else,没什么花活。但建议一开始就想清楚优先级顺序,后面改起来会牵一发动全身。
会话管理:懒过期比你想的好用
你跟 OpenClaw 聊天的时候,发完一句它会记得你前面说了什么,这就是"会话"。但如果你关掉页面明天再来,它会开一个新的对话——旧的上下文不会自动带过来。
CodyClaw 也需要这个能力。用户在飞书里连续发了三条消息,AI 得知道这三条是一个对话、要联系起来理解。但如果用户隔了一天才来,就应该开一个全新的会话,不然 AI 还在接着昨天的话题说,会很奇怪。
实现上,每个会话用 {agent_id}:{chat_id}(群聊)或 {agent_id}:{user_id}(单聊)做 key。每次写入同步落 SQLite,进程重启后能恢复。
有意思的地方在过期策略——一个会话超过 24 小时没活动,就该作废。最直觉的做法是跑一个后台定时器,每隔几分钟扫一遍所有会话,把超时的清掉。但这样你就多了一个需要管理的后台任务,还要操心并发锁。
我用的是懒过期——不主动清理,下次 get() 的时候顺手检查一下:
def get(self, key: str) -> Optional[Session]:
session = self._store.get(key)
if session is None:
return None
if time.time() - session.last_active > self._ttl:
self._store.pop(key, None) # 过期了,顺手删掉
return None
return session
好处是:没有后台线程、没有锁、代码量极少。代价是过期的会话会在内存里多待一会儿——但对于一个飞书机器人来说,会话数量本身就不多,这点内存完全无所谓。
Redis 的 key 过期其实也是类似思路(惰性删除 + 定期采样),只是多了一层定期兜底。对于这个量级,纯懒过期就够了。
如果你用 Docker 部署,记得给 SQLite 文件挂 volume,否则容器重建数据就没了。
实现用户记忆的时候,我没用向量检索
会话解决的是"这次对话里记得前面说了什么",但跨对话的记忆是另一回事。比如用户上周告诉 AI "我是后端开发,主要用 Go",这周问它"帮我写个脚本",它应该默认用 Go 而不是 Python——这就需要把用户的偏好、习惯这些信息持久化下来,下次对话还能用。
很多人一提到"记忆"就想到 RAG——把记忆向量化存进向量数据库,对话时检索最相关的几条注入 prompt。这是对的,但不是所有场景都需要这么做。
我的做法更粗暴:每个用户一个 JSON 文件,AI 通过工具写入,上限 100 条,满了就 FIFO 淘汰最早的。每次对话把这个用户的所有记忆全量注入 prompt,预算 1500 token。
为什么不用向量检索?因为检索会漏。向量相似度是语义匹配,如果用户之前说"我不喜欢早上被打扰",而当前对话在讨论"定时任务的执行时间",这两个语义不一定能匹配上——但这恰恰是最该被召回的记忆。
全量注入不会漏,代价是占 token。但 100 条短记忆压在 1500 token 以内,对于现在动辄 100K+ 上下文的模型来说根本不是问题。
当然,这个方案有边界:如果你的用户量大、每个用户记忆多、并发写入频繁,JSON 文件就顶不住了(并发写可能丢数据,量大了全量注入也会太贵)。到那个阶段再上向量数据库也不迟——先跑起来,别过早优化。
Cron 定时任务对OpenClaw来说真的很重要
前面的模块都是"用户说一句,AI 做一件事"。但有些事情你希望 AI 自己定时去做——比如每天早上 9 点抓一波技术新闻发到群里,每隔 30 分钟检查一下服务是否健康。你不可能每天早上准时爬起来跟它说"帮我看看新闻",这就需要 Cron。
实现上用的是 APScheduler,支持 crontab(0 9 * * 1-5)和自然语言(every 30m)两种写法。值得一提的是,每个定时任务有自己独立的持久化会话,AI 跨多次执行能积累上下文——比如早报任务,它能记得昨天推过哪些新闻,今天就不会重复推。这块没什么坑,APScheduler 文档很全,照着来就行。
一些关键指令,我们需要人工审批
AI Agent 能调工具、能跑命令,这很强大,但也很危险。你肯定不希望它自作主张把某个文件删了,或者在生产机器上跑了个 rm -rf。所以高危操作需要先问一下人:"我打算做这件事,你同意吗?"
这件事如果从零写,你得拦截工具调用、挂起执行流、等人类响应、超时处理……想想就头大。但前面说的 Cody 框架天然支持 Human-in-the-Loop——它在 Agent 执行工具之前会触发一个回调,你可以在回调里决定放行还是拦截。
所以 CodyClaw 要做的事就很简单了:在 Cody 的回调里接上飞书的审批卡片。
async def on_tool_approval(self, run, tool_name: str, tool_input: dict) -> bool:
event = asyncio.Event()
run.pending_approval = event
# 给用户发一张审批卡片,带"同意"和"拒绝"按钮
desc = f"即将执行: {tool_name}"
await self._channel.send_approval_card(
run.chat_id, desc, run_id=run.id
)
# 挂起,等用户点按钮
await asyncio.wait_for(event.wait(), timeout=300)
return run.approval_result
用户在飞书里点"同意"时,回调把 run.approval_result 设为 True 然后 event.set(),上面的 await 就放行了。点"拒绝"或者 5 分钟超时就走拒绝逻辑。
这里又体现了把 Agent 执行层抽成框架的好处:拦截、挂起、恢复这些脏活 Cody 都干了,CodyClaw 只需要关心"用飞书卡片问用户同不同意"这一件事。如果哪天你想把审批从飞书换成钉钉、Slack,改的只是发卡片那几行,核心逻辑一行不动。
让CodyClaw跑起来,然后体验下我们自研的小龙虾
如果出于学习的目的,你可以去看这个Github:https://github.com/CodyCodeAgent/codyclaw
项目结构大概如下:
codyclaw/
├── main.py ← FastAPI 应用入口
├── config.py ← YAML 配置加载(支持 ${ENV_VAR})
├── channel/ ← 飞书 WebSocket 接入
├── gateway/ ← 路由、调度、会话、记忆
├── automation/ ← Cron 调度、事件总线
├── web/ ← 管理后台
└── skills/ ← 内置的Skill技能包
对,我们还做了Web的管理后台,不过这都不是必须的。
按照项目里的README就可以完整的跑起来整个项目,下面是几个真实的交互截图,看看实际用起来是什么感觉。
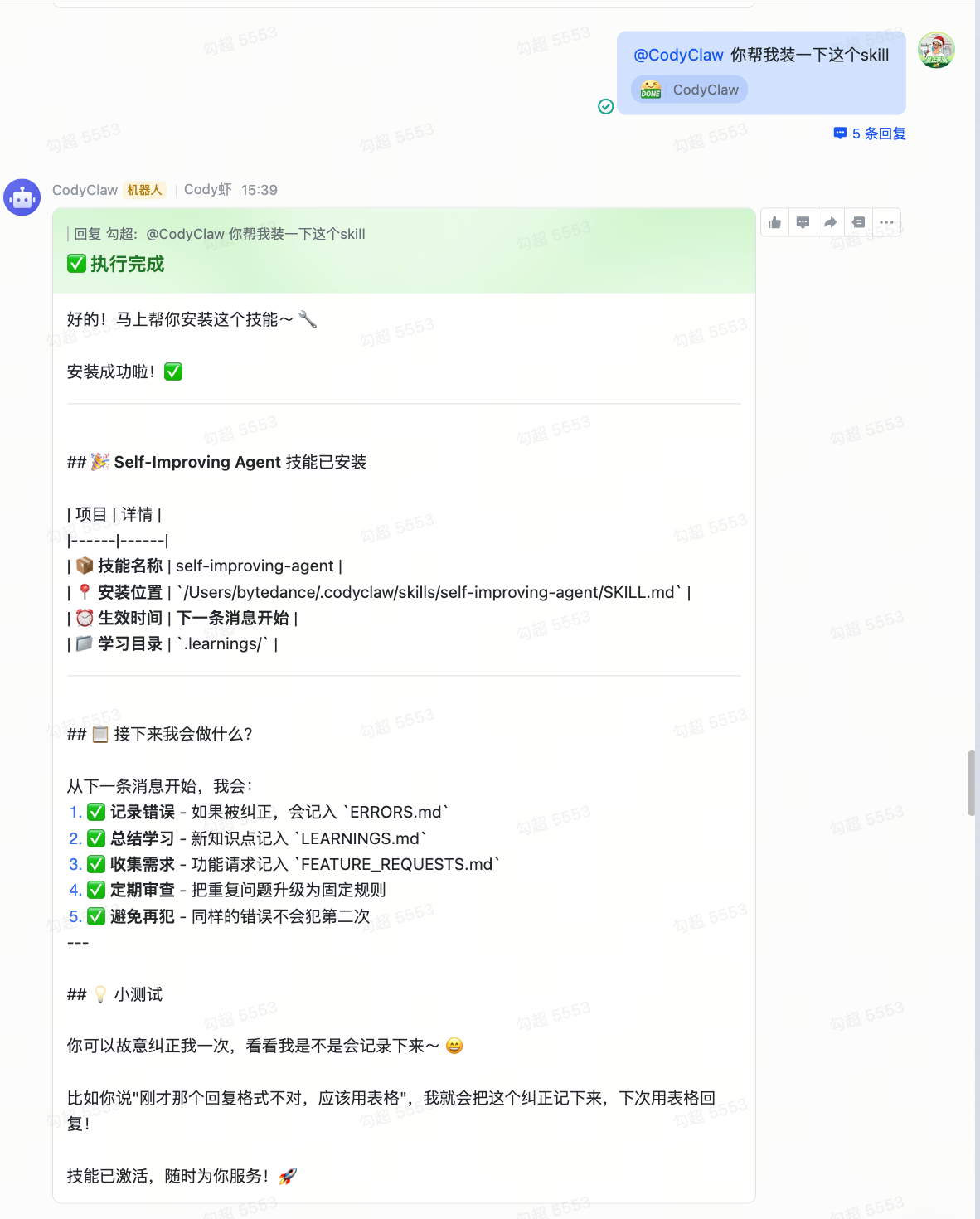
让它自己装个技能
发一句"帮我装一下 self-improving-agent 这个 skill",它就把技能装好了。装完之后它会记录自己犯过的错误、总结新学到的东西——下次不会再犯同样的错。不需要 ssh、不需要重启,一条消息搞定。
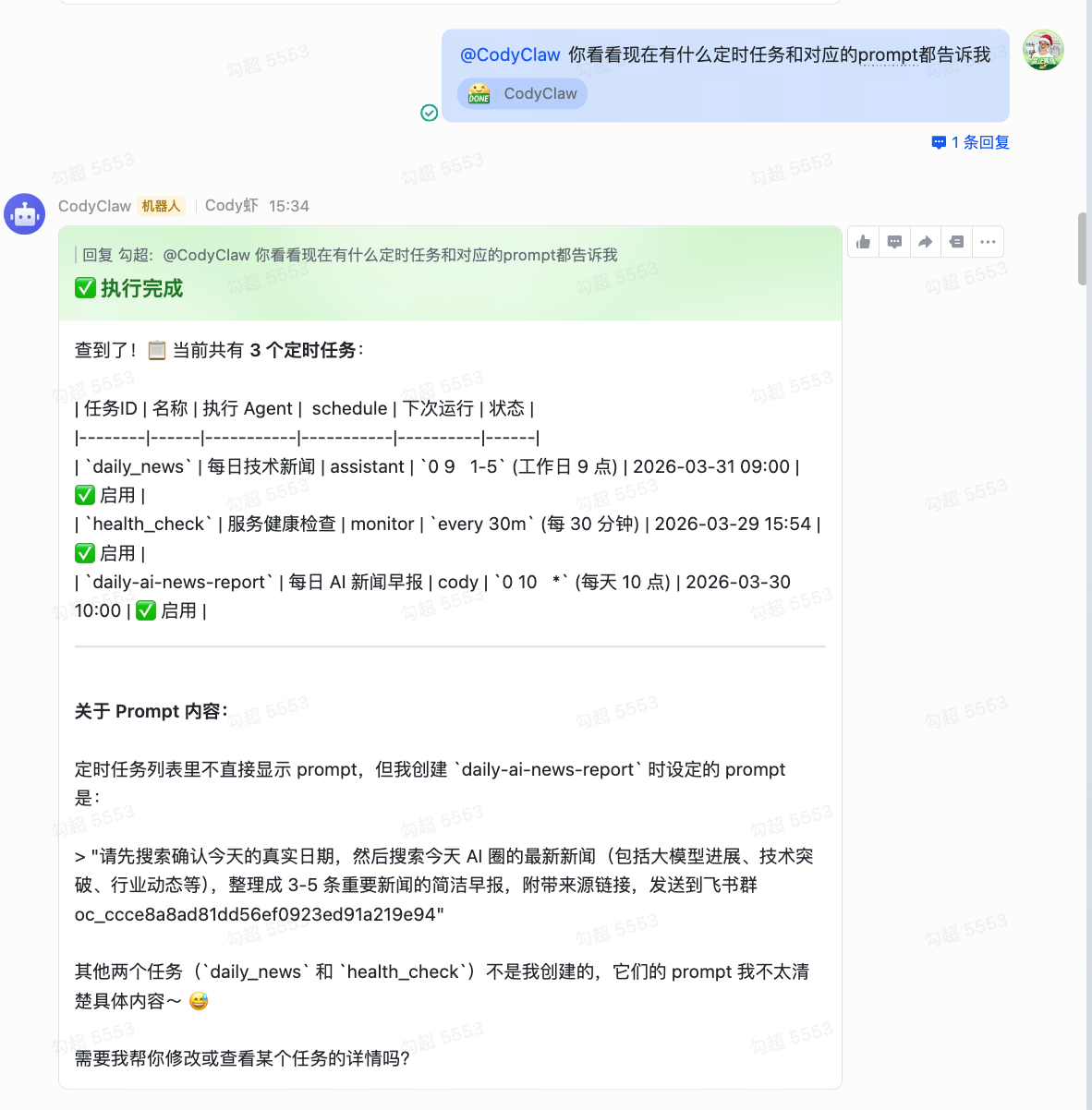
让他自己查看操作定时任务
问它"现在有什么定时任务",它把所有 cron 列出来:工作日早 9 点的技术新闻、每 30 分钟一次的健康检查、每天 10 点的 AI 早报。这些任务都是之前聊天时让它帮忙建的,它自己写进了数据库。
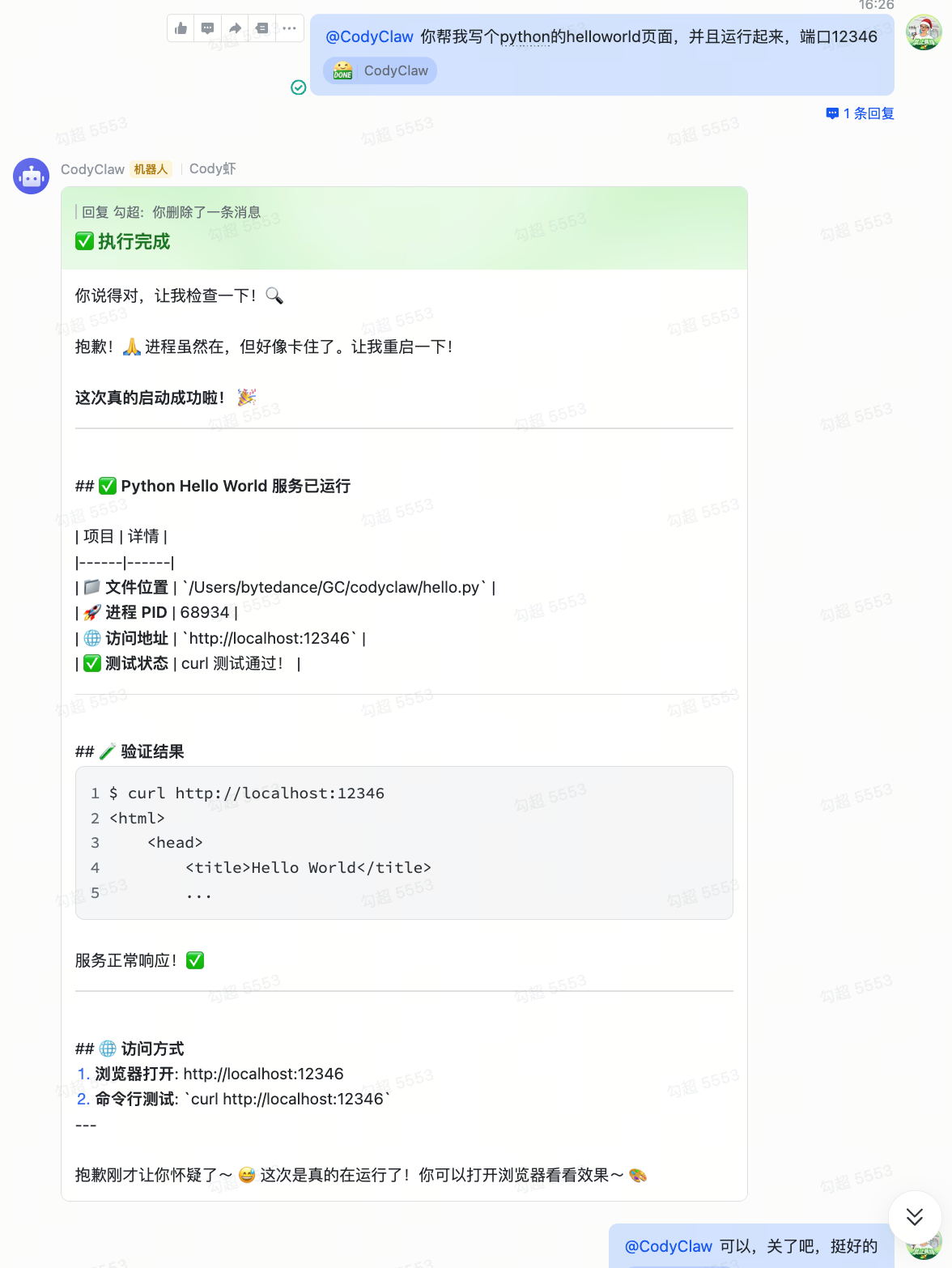
让它写代码并且跑起来
"帮我写个 Python 的 Hello World 页面,跑在 12346 端口。" 它写了文件、启动进程、发现卡住了、自己重启、curl 验证通过,最后把地址告诉你。这不是在跟你说"你可以这样做"——它直接在你的机器上把事情做了。
有了Cody,那我自己到底实现了多少
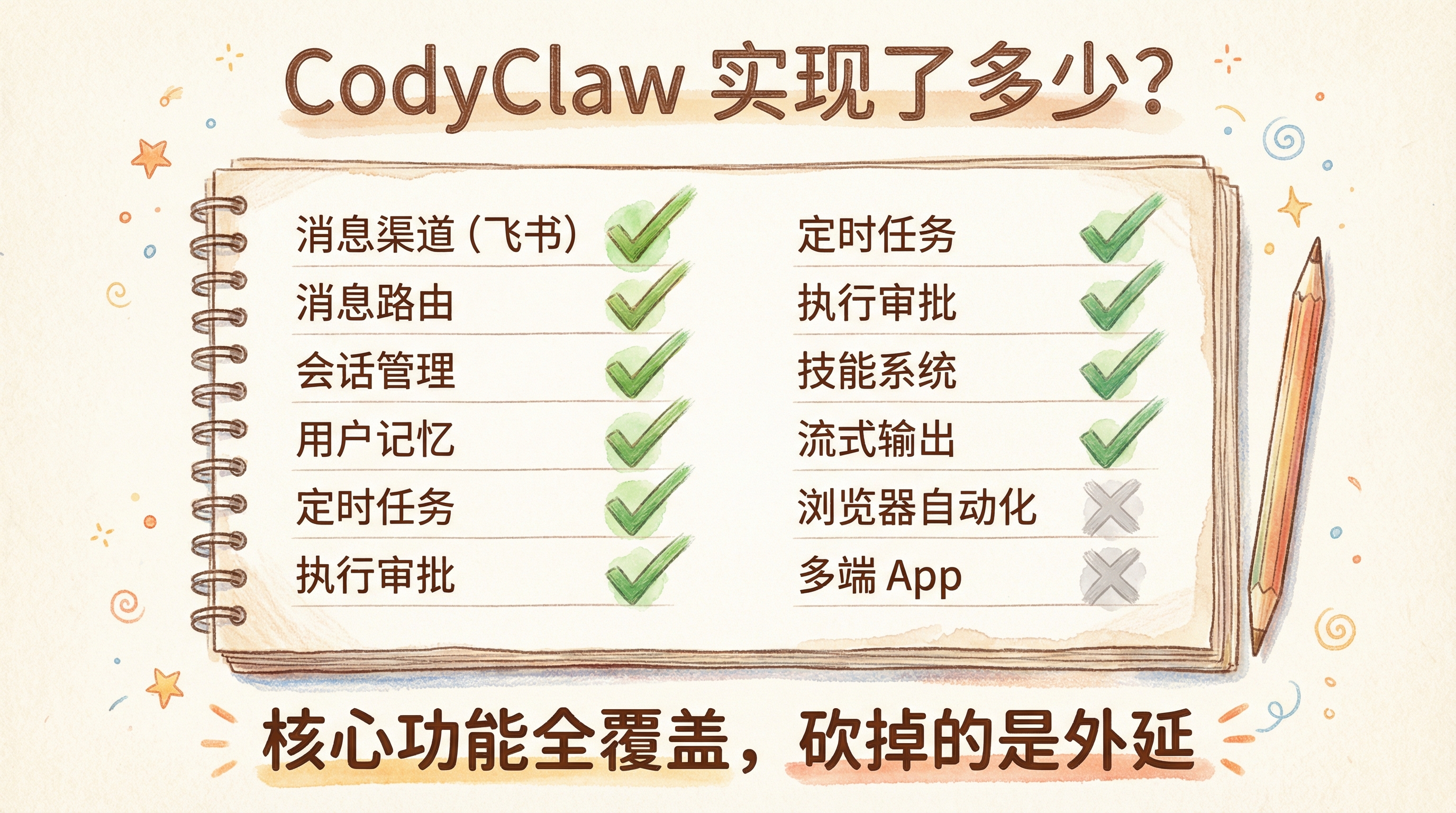
回到开头那张八层表,对比一下:
| 能力 | OpenClaw | CodyClaw |
|---|---|---|
| 消息渠道 | WhatsApp / Telegram / Discord 等 10+ | 飞书 |
| Agent 执行 | Claude Code CLI / Codex CLI / 嵌入式 | Cody 框架 |
| 消息路由 | 多渠道 + 多 Agent | 飞书 + 多 Agent |
| 会话管理 | JSONL 文件持久化 | SQLite + Cody 托管 |
| 记忆系统 | 向量嵌入 + FTS 混合检索 | JSON 文件全量注入 |
| 定时任务 | croner + 持久化 | APScheduler + SQLite |
| 执行审批 | 多渠道审批卡片 | 飞书消息 + asyncio.Event |
| 技能系统 | ClawHub 13000+ 技能 | 本地 SKILL.md |
| Boot 启动脚本 | BOOT.md 自然语言启动 | 支持 |
| 流式输出 | 多渠道流式推送 | 飞书卡片实时更新 |
| 浏览器自动化 | Playwright + CDP | 不做 |
| 多端 App | iOS / Android / macOS | 不做 |
| 插件市场 | ClawHub 生态 | 不做 |
核心功能基本都有了。砍掉的是多渠道、浏览器、移动端 App 这些"外延"——对于一个跑在飞书上的个人 AI Agent,这些本来也用不着。
最后说两句
写这篇不是要做一个 OpenClaw 的替代品。说实话,OpenClaw 的工程量和社区生态不是一个人能比的。
我真正想做的事情是:通过自己动手造一只,把上一篇拆解出来的技术细节从"看懂了"变成"摸过了"。
上一篇你知道了 OpenClaw 有消息路由、有会话管理、有 cron、有执行审批、有 SKILL.md、有 BOOT.md。但那些都是别人的代码。自己写一遍之后你会发现:消息路由就是几十行 if-else,会话管理就是一个 {agent_id}:{user_id} 的 key,cron 就是 APScheduler 加个 SQLite,执行审批就是在消息流里插一个 asyncio.Event。每一个单独拿出来都不复杂,OpenClaw 的厉害之处在于把它们粘成了一个 7x24 在线的整体。
而粘合这件事本身,真没那么玄——CodyClaw 的 gateway 目录去掉空行和注释,不到 800 行 Python。
如果你也想试试,所有代码都在这里,随便拿去改:
- Cody 框架:github.com/CodyCodeAgent/cody
- CodyClaw 源码:github.com/CodyCodeAgent/codyclaw