没有标准数据集,如何客观评测算法效果?

我们团队做了多年自研算法,最近遇到一个棘手的问题:新算法理论上更好,但无法客观证明。这篇文章分享我们从零开始设计评测体系的思路,以及背后借鉴的业界方法论。
一、问题从哪里来
团队的自研算法已经跑了好几年了,线上版本整体稳定。随着持续迭代,新版本出来了——直觉和小范围测试都感觉好不少。但老板问"能不能证明新算法更好、好多少"的时候,我们沉默了。
问题出在哪?历史积累的标注数据,是由当前算法自己打的标签。 用"当前算法的判断"来评测新算法,像让运动员给自己裁判,偏差是天然存在的。
而且这不只是一个数据问题,暴露出来的是整套评测体系的缺失:
- 没有标准数据集:历史标注由当前算法产出,不中立
- 人工标注成本高:全靠人工既慢又贵,难以规模化
- 没有评测机制:每次评估都要从零开始,结论无法横向对比
- 切换决策没有依据:算法切换是高风险操作,不能只靠直觉
二、业界是怎么解决这类问题的
着手设计方案前,我们调研了业界的成熟做法。有意思的是,这些方法各自解决一个子问题,拼在一起刚好能覆盖我们的困境。
1. LLM-as-Judge:让 AI 当裁判
没有标准答案,能不能让一个够强的 AI 来替代人工做判断?
这就是 LLM-as-Judge 的出发点。MT-Bench(NeurIPS 2023)的研究表明,GPT-4 与人类专家的评判一致率超过 80%。更重要的是,AI 裁判不只给分,还会解释理由——而这些理由本身就是定位算法问题的线索。
当然 AI 裁判也有自己的偏见:
- 位置偏见:倾向于选排在前面的答案(对策:评两次并交换顺序)
- 啰嗦偏见:回答越长越容易高分(对策:评分细则里明确"不因长度加分")
- 自恋偏见:偏好与自身风格相近的内容(对策:换不同家族的模型当裁判)
对我们来说,LLM-as-Judge 最大的价值不是"替代人工打分",而是用来生产标准数据集。让 LLM 和现有算法同时跑一批数据,盯着分歧案例让人工仲裁——LLM 承担初筛,人工只处理真正有争议的地方,成本直接降一个数量级。
2. Weak Supervision:让不完美的规则联合投票
数据量大的时候,不可能每条都过 AI 裁判。弱监督提供了一条批量打标的路。
思路很直接:把多个"不完美但有用的信号"组合起来投票。比如:
- 现有算法的判断(准确率 70%)
- 大模型的判断(准确率 85%)
- 规则判断:文本长度差异超过 50%(准确率 60%)
单看每条规则都不够可靠,但斯坦福开发的 Snorkel 框架能自动推算每条规则的可信度,加权投票后准确率大幅提升。关键是不需要任何标准答案——它靠规则之间的"同意/打架"模式反推各规则的可靠性。这个方案 Google 已经在工业规模落地(DryBell,2019)。
LLM-as-Judge 解决质量问题(谁来判断对错),弱监督解决规模问题(怎么批量打标)。前者精但慢,后者快但粗——两者配合,弱监督负责大批量初标,LLM-as-Judge 负责精细复核。
3. Active Learning:让模型告诉你标哪些数据最值钱
标注预算有限,怎么把钱花在刀刃上?
主动学习的答案是:标那些模型最拿不准的数据,因为标了之后进步最大。就像一道一眼就会的题做了没什么收获,而那道做到一半卡住的题,看答案才真的有提升。
具体策略之一是分歧采样:让多个模型对同一条数据投票,意见最不一致的优先标注。这和我们的直觉不谋而合——评测时优先看各算法分歧大的案例,本质上就是主动学习。
4. ELO 评分:不需要标准答案的排行榜
王者荣耀的段位系统背后是 ELO 算法:不需要知道每个人的"绝对实力",只需要积累大量"A 和 B 谁赢了"的相对比较,就能得出全局排名。
在算法评测里,它的价值在于:在标准数据集还不够多的早期,先给出一个相对排名,让初步决策有据可依。
具体操作:让各算法对同一批数据分别给出判断和解释,由 AI 裁判选"哪个解释更有道理",记录胜负。积累几百次 PK 之后,排行榜自然浮现。
这套机制还天然支持多维度评价——不只看结论对不对,也评推理过程合不合理。两个算法都答对了,但一个靠真正理解语义,另一个靠碰巧匹配关键词,只看结论是区分不出来的。
5. Data Flywheel:把前四个方法串成闭环
前四个方法各自解决评测的某个子问题。数据飞轮不是一个新方法,而是一种设计理念——把这些方法连成一个持续自动迭代的闭环,让整个体系越用越好。
微软的 Arena Learning(2024)是目前最先进的工程实践:用 AI 模拟对战替代人工投票,效率是人工方式的 40 倍,与人类判断一致率达到 98.79%,整个训练过程几乎不需要人工介入。
三、我们的设计:自举评测飞轮
把上述方法论落到具体场景,核心是一个自举(Bootstrapping)的评测飞轮:
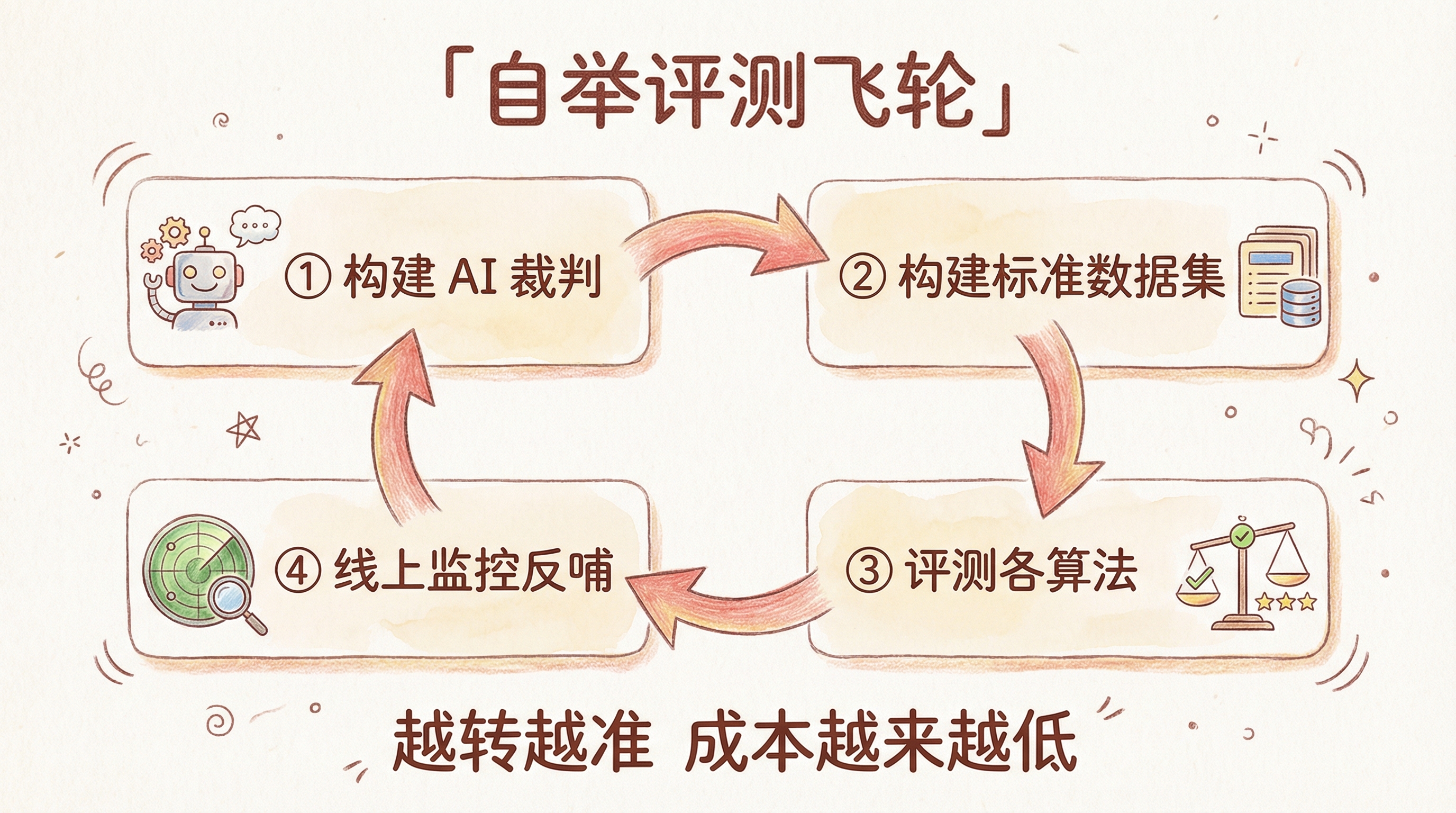
整个体系的核心是 AI 裁判 Agent——它不是静态的打分工具,而是一个会持续成长的 Agent:
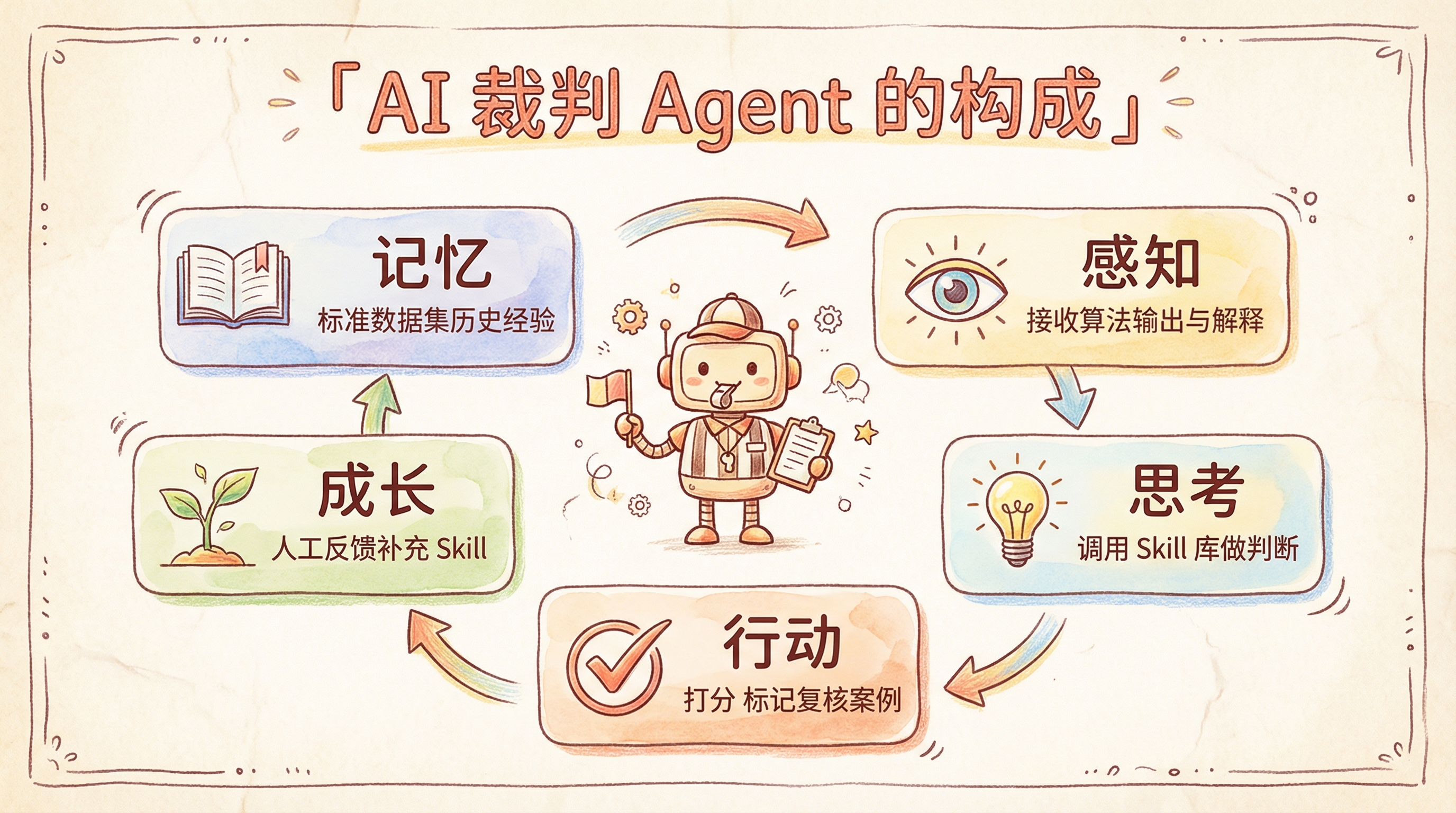
其他所有模块——标准数据集、难例库、Skill 库、报告层——都在围绕这个 Agent 服务。
四、系统模块设计
完整系统由以下模块构成:
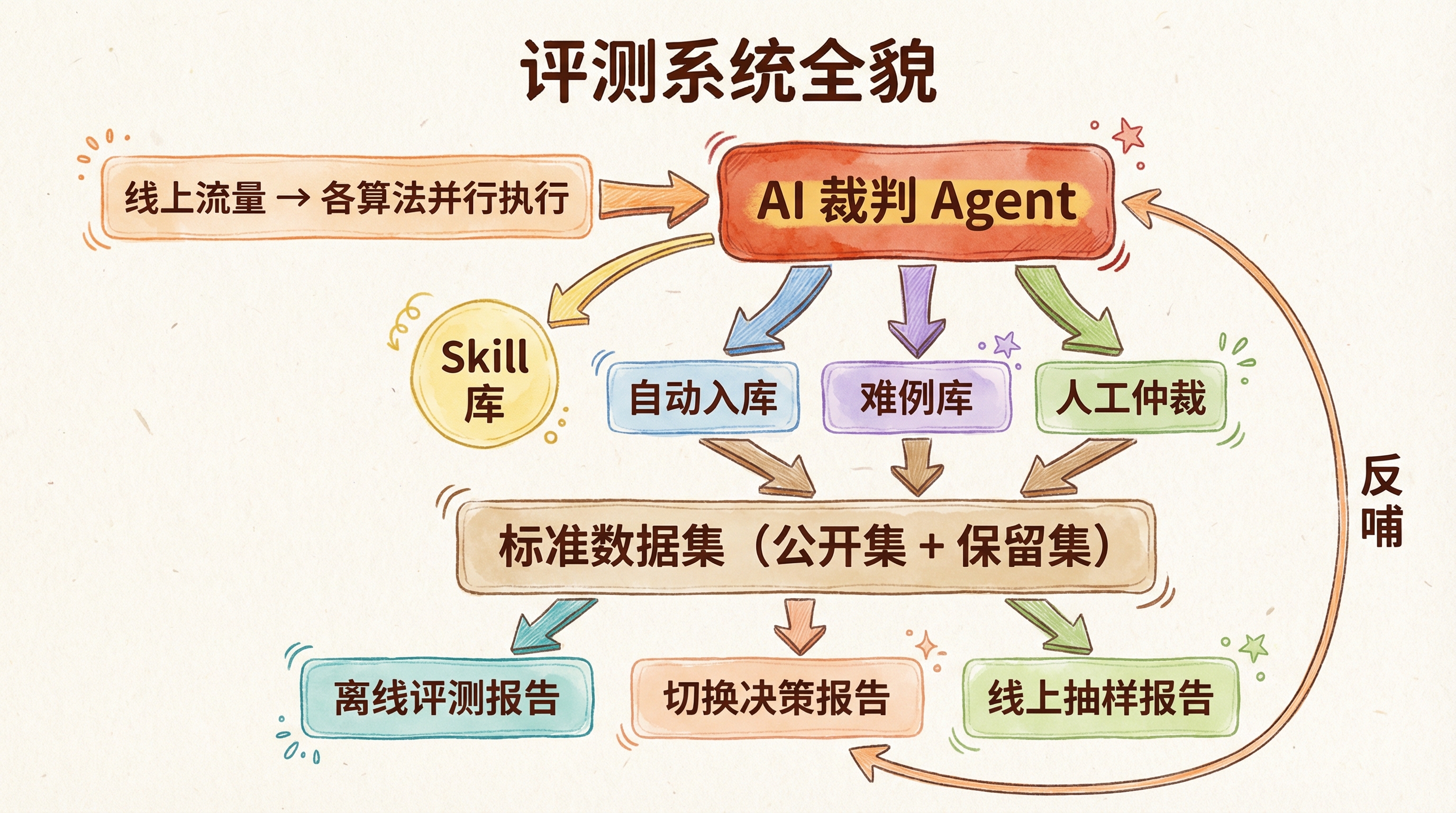
几个关键设计决策值得单独说:
标准数据集分公开集和保留集。 公开集供算法调优参考,保留集只在最终评测时用。防止算法针对评测集过拟合("刷榜")——这和 Kaggle 的 public/private leaderboard 设计同理。
难例库单独管理。 各算法分歧大、人工也难判断的边界案例单独收录。这批数据是提升 AI 裁判天花板的核心资产,也是算法改进最值得攻坚的方向。
评测结果要版本化。 AI 裁判在升级,标准数据集也在扩充。如果评测结果不绑定具体的裁判版本和数据集版本,历史数据就失去了可比性。
五、落地路径
MVP:先回答"新算法是否比当前算法更好"
MVP 不追求完整系统,只要能支撑第一次切换决策就够了:
- 定义评分维度:明确从哪几个维度打分,为每个维度写评分细则
- 搭基础 AI 裁判:把维度和细则写入 Prompt,跑通单条打分
- 采集 300-500 条数据:重点选各算法分歧大的案例,少量随机抽取防止盲区
- 人工标注:逐条确认正确答案,建立初始标准数据集(⚠️ 标注人员需要有领域判断力,这一步偷不了懒)
- 跑离线对比评测:AI 裁判对各算法输出打分,人工复核不确定案例
- 归因 AI 裁判的错误:补充 Skill,迭代直到准确率 ≥ 85%(⚠️ 需提前定好阈值,避免无限迭代)
- 输出切换决策报告:指标对比 + 典型错误案例 + 切换风险评估
第二阶段:扩充评测基准
- 建立难例库,对高频错误类型专项攻坚
- 引入多信号融合批量生成初始标签,降低人工成本
- 标准数据集切分公开集 / 保留集
第三阶段:线上持续监控,形成飞轮
- 线上流量分层抽样,自动进入评测流程
- 周期性输出质量报告,设置报警阈值
- 线上发现的新难例自动进难例库,人工复核结果反哺 AI 裁判
- 引入 ELO/Pairwise 排行榜,作为标准数据集评测的补充
六、几个反直觉的地方
回顾整个体系,有几点讨论时觉得别扭,但仔细想都有道理:
LLM 不是用来替代人工的,是用来生产 GT 数据的。 很多人提到 LLM-as-Judge,第一反应是"用 AI 替代人工打分"。但在没有标准数据集的阶段,LLM 更大的价值是充当 GT 数据的初筛器——它处理大量案例,人工只处理 LLM 和算法产生分歧的那一部分。
ELO 不是成熟后用的,是数据集不够时用的。 很多人会觉得 ELO 是更"高级"的评测方式,应该等体系成熟后再上。但它真正的价值在早期——标准数据集还不够的时候,用 ELO 先给出相对排名,支撑初步决策。数据集建好后,ELO 反而退场。
评算法不只评结论,还要评推理过程。 两个算法都答对了,但一个靠真正理解语义,另一个靠碰巧匹配关键词——只看结论无法区分。评推理过程,才能判断算法在新场景下的泛化能力。
七、总结
这套方案的本质,是用自举 + 飞轮的方式,绕开"没有 GT 就无法评测"的死结:
- 用 LLM 做初始裁判,生产第一批 GT 数据
- 用主动学习,把有限的人工精力花在最值钱的地方
- 用弱监督,在数据集扩充阶段降低成本
- 用 ELO,在数据集不足时提供相对排名
- 把以上连成飞轮,让整个体系自动越转越好
这套方法论不局限于我们的场景,任何面临缺乏标准数据集、需要客观评测多版本算法问题的团队,都可以参考这个框架。
飞轮刚开始推很费力,但只要转起来,就会越来越省力。
参考文献
- Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena(Zheng et al., NeurIPS 2023)
- G-Eval: NLG Evaluation using GPT-4(Liu et al., EMNLP 2023)
- Snorkel: Rapid Training Data Creation with Weak Supervision(Ratner et al., VLDB 2018)
- Chatbot Arena: An Open Platform for Evaluating LLMs(LMSYS, 2024)
- Arena Learning: Build Data Flywheel for LLMs Post-training(Microsoft Research, 2024)