Cody:把 Harness Engineering 装进一个框架
- 从 Harness Engineering 说起
- Cody 是什么
- Cody 是怎么实现 Harness 三根柱子的
- 好,那 SDK 用起来是什么感觉
- Harness 很重要,但搭 Harness 不应该是每次都从零开始
- 与现有方案的对比
- 目前的状态
- 最后

上一篇我提到,造 CodyClaw 的时候把 Agent 执行层抽了出来,做成了独立框架,叫 Cody。当时是一句带过。
但其实 Cody 背后有个更完整的出发点,跟更早那篇 Harness Engineering有很深的关系。这篇专门来讲透。
从 Harness Engineering 说起
如果你没读过那篇 Harness 的文章,这里快速摘要一下核心观点:
决定 Agent 干活质量的,不是模型多聪明,是你给它搭的环境多靠谱。
Philipp Schmid 打了个比方:Model 是 CPU,Context Window 是 RAM,Harness 是操作系统,Agent 是应用程序。
一个好的 Harness 干四件事:
- 约束——Agent 能干啥不能干啥(文件权限、危险命令、行为边界)
- 告知——Agent 该干啥(上下文、规范、项目记忆)
- 验证——Agent 干对没有(测试、linter、反馈循环)
- 纠正——干错了怎么修(回滚机制、自修复、Human-in-the-Loop)
读完那篇之后我意识到一件事:每次造一个新的 AI Agent 应用,你都要从零搭一个 Harness。
而搭 Harness 的那些活——权限控制、文件访问边界、危险命令拦截、熔断器、会话管理、流式输出、项目记忆——这些东西跟你的业务逻辑完全无关,但每次都要重新写一遍。
这就是 Cody 想解决的问题:把 Harness Engineering 方法论固化成一个可复用的 Python 框架,让你不用每次都从零搭 Harness,直接拿来用就行。
Cody 是什么
一句话定位:Cody 是一个开源 AI Agent 框架,它把 Harness Engineering 的三根柱子做成了框架的内置能力,让你用几行代码就能跑起来一个带完整 Harness 的 Agent。
它不是一个 AI 产品,不是一个聊天机器人,也不是一个玩具——它是给开发者用的框架,是你应用代码和底层模型之间的那个操作系统层。
接入方式有四种:Python SDK(最核心,本文主要讲这个)、CLI、TUI 终端界面、Web 浏览器界面。四种方式共享同一个核心引擎,能力完全一致。
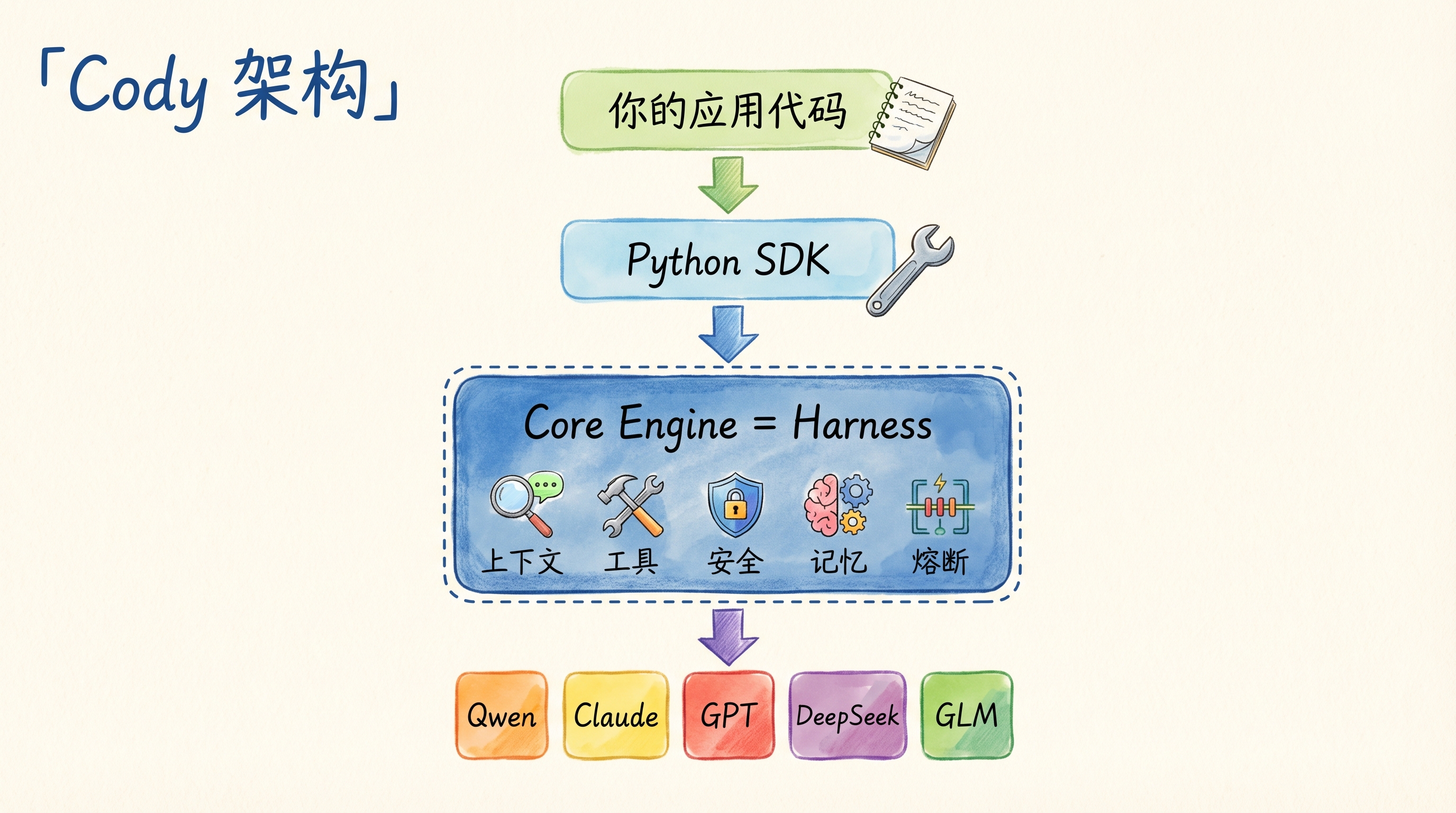
Cody 是怎么实现 Harness 三根柱子的

Harness 有三根柱子:上下文工程、架构约束、熵管理。来一根根对照看 Cody 做了什么。
柱子一:上下文工程——让 Agent 看到该看的
Harness 这根柱子的核心是:Agent 看不到的东西等于不存在。 所以你要把一切有用的知识主动喂给它。
Cody 的做法:项目记忆(Project Memory)
Agent 跑完一次任务后,它对项目积累的理解可以持久化。下次启动时自动注入,不用每次从头介绍项目背景。
result = await client.run("重构 auth.py,让异常处理更统一")
# Agent 读取保存的项目记忆:
# - 这个项目用 type hints
# - black 格式化,行宽 100
# - 异常统一抛 AppError,不用 ValueError
# - 测试放在 tests/ 目录,用 pytest
# 按规范改,不按自己的默认习惯改
这相当于给 Agent 写了一份动态更新的 CLAUDE.md / AGENTS.md,但不需要你手动维护——Agent 自己跑、自己总结、自己写进记忆。
Cody 的做法:Skills 系统
Skills 是 SKILL.md 格式的知识模块,告诉 Agent 特定任务的上下文和约束。符合 agentskills.io 开放标准,26+ AI 平台都认。
client = (
Cody()
.workdir(".")
.skills_dirs(["./skills", "~/.agents/skills"]) # 从这些目录加载 Skills
.build()
)
Skills 是按需加载的——Agent 在处理某个任务时判断需要用哪个 Skill,然后读进上下文。这就是 Harness Engineering 里说的渐进式披露:不在启动时一股脑塞所有信息,让信息随任务推进按需浮现。
Cody 的做法:可定制 System Prompt
你可以在 Cody 的 system prompt 里注入项目规范、代码风格、禁止事项——就是 Harness 文章里 CLAUDE.md 那些内容,直接通过 SDK 注入:
client = (
Cody()
.workdir(".")
.system_prompt_extra("""
代码规范:
- 函数不超过 50 行
- 所有公开函数必须有类型注解
- 异常统一用 AppError,不用通用 Exception
- 禁止在 Service 层写 SQL
""")
.build()
)
柱子二:架构约束——让 Agent 不做不该做的
Harness 这根柱子的核心是:别跟 Agent 讲道理,直接拦住它。
Cody 的做法:文件访问边界(allowed_roots)
Agent 只能读写你明确允许的目录,路径遍历攻击直接在框架层拦截,不依赖 Agent 自觉。
client = (
Cody()
.workdir("/safe/project")
.allowed_roots(["/safe/project", "/tmp"]) # 只能访问这两个目录
.build()
)
# Agent 尝试读 /etc/passwd → ToolPathDenied,直接报错
# Agent 尝试访问 /other/project → ToolPathDenied,直接报错
Cody 的做法:危险命令拦截(blocked_commands)
Shell 命令白名单 / 黑名单,在执行前检查,不通过直接拒绝。
client = (
Cody()
.blocked_commands(["rm -rf /", "sudo rm", "dd if=", "mkfs"]) # 这些直接拦
.build()
)
Cody 的做法:工具级权限控制
每个工具可以配置执行策略:自动执行、直接拒绝、或者每次都要人工确认。
client = (
Cody()
.tool_permission("exec_command", "confirm") # Shell 执行必须人工确认
.tool_permission("write_file", "allow") # 写文件自动放行
.tool_permission("spawn_agent", "deny") # 禁止启动子 Agent
.build()
)
Cody 的做法:熔断器(Circuit Breaker)
这是 Harness 里 Loop Detection 的升级版。Harness 文章里 LangChain 的做法是"追踪文件编辑次数,超过 N 次就中断"。Cody 做得更系统:
client = (
Cody()
.max_tokens(50_000) # token 消耗超过就停
.max_cost(2.0) # 花费超过就停(美元)
.max_steps(30) # 工具调用轮次超过就停
.build()
)
这三个参数是硬约束,不是建议。熔断后 run() 返回截止那一刻的结果,result.circuit_breaker_triggered 会告诉你是否触发了熔断。这解决了 Harness 文章里说的 Agent Drift 问题——跑偏了不会无限消耗资源,有个兜底在。
Cody 的做法:Human-in-the-Loop
有些操作你希望 Agent 先问你再做。Cody 把这个做成了框架层面的一等公民:
from cody.sdk import Cody, InteractionRequestChunk
async with Cody().workdir(".").build() as client:
async for chunk in client.run_stream("把这个服务部署到生产环境"):
if isinstance(chunk, InteractionRequestChunk):
print(f"\nAgent 需要确认:{chunk.question}")
print(f"选项:{chunk.options}")
answer = input("你的决定:")
await client.send_user_input(answer, session_id=chunk.session_id)
elif chunk.type == "text_delta":
print(chunk.content, end="", flush=True)
Agent 调内置的 question 工具时,执行流挂起、等你回答、拿到回答后继续——整个流程在框架内完成,不需要你自己实现状态机。这就是 CodyClaw 里飞书审批卡片那个能力的来源,上一篇讲过。
柱子三:熵管理——让系统不会越跑越烂
Harness 这根柱子的核心是:AI 生成的内容天然趋向混乱,需要主动管理。
Cody 的做法:文件 Undo / Redo
Agent 改了文件,改坏了怎么办?Cody 内置文件变更追踪,Agent 可以调 undo_file 回滚,你也可以通过 SDK 主动回滚:
# Agent 自动回滚(Agent 自己判断改错了)
# 或者你从外部强制回滚
await client.run("回滚刚才对 config.py 的修改")
Cody 的做法:审计日志(Audit Logger)
所有工具调用、文件变更、Shell 执行都落 SQLite 日志,可以事后审查 Agent 干了什么、按什么顺序干的。这对应 Harness 文章里说的"可观测性"——Agent 每次犯错都是一条有价值的信号,你得先看见才能改进。
Cody 的做法:流式事件系统
run_stream() 的 chunk 不只是文字,是分类型的结构化事件:
async for chunk in client.run_stream("重构这个模块"):
if chunk.type == "text_delta":
print(chunk.content, end="", flush=True)
elif chunk.type == "tool_call":
print(f"\n→ 调用工具: {chunk.tool_name}({chunk.tool_input})")
elif chunk.type == "tool_result":
print(f"← 结果: {chunk.content[:100]}...")
elif chunk.type == "thinking":
print(f"[思考]: {chunk.content}") # 如果模型支持 thinking mode
elif chunk.type == "circuit_breaker":
print(f"[熔断]: {chunk.reason}")
elif chunk.type == "retry":
print(f"[重试 {chunk.retry_attempt}/{chunk.retry_max_attempts}]: {chunk.content}")
elif chunk.type == "done":
print(f"\n总计: {chunk.total_tokens} tokens,${chunk.cost:.4f}")
整个执行过程完全透明。Harness 文章里说"成功应该是沉默的,只有失败才需要产出"——这套事件流就是让你能区分成功的噪音和真正需要关注的信号。
好,那 SDK 用起来是什么感觉
说完设计,说说实际用法。Cody SDK 的核心就一个类:AsyncCodyClient。
最简单的起点
安装只需要:
pip install cody-ai
核心依赖就四个:pydantic-ai、pydantic、httpx、sqlite3。不会把你的依赖树搞得一团糟。
然后配模型——用环境变量,不硬编码在代码里:
export CODY_MODEL=qwen3.5-plus
export CODY_MODEL_BASE_URL=https://coding.dashscope.aliyuncs.com/v1
export CODY_MODEL_API_KEY=sk-xxx
跑第一个任务:
import asyncio
from cody.sdk import AsyncCodyClient
async def main():
async with AsyncCodyClient(workdir="/path/to/project") as client:
result = await client.run("给 utils.py 里所有公开函数加上类型注解")
print(result.output)
print(f"用了 {result.total_tokens} tokens")
asyncio.run(main())
这几行代码背后,Cody 会自己读文件、理解代码结构、写改动。你不需要告诉它"先调 read_file,再调 edit_file,再调 read_file 验证"——它知道该怎么干,工具调用的顺序是模型自己规划的,Harness 负责执行时的约束。
多轮对话:Agent 记得前面说了什么
run() 可以通过 session_id 串联成多轮对话:
async with AsyncCodyClient(workdir="/path/to/project") as client:
# 第一步:创建应用骨架
r1 = await client.run("创建一个 Flask 应用,包含 /api/users 的 CRUD 路由")
print(f"Session: {r1.session_id}")
# 第二步:在同一个会话里继续,Agent 记得第一步做了什么
r2 = await client.run(
"给 /api/users/create 加上参数校验,邮箱格式检查和必填字段检查",
session_id=r1.session_id
)
# 第三步:继续加功能
r3 = await client.run(
"写完整的单元测试,覆盖正常路径和边界情况",
session_id=r1.session_id
)
会话状态由 Cody 托管,SQLite 落盘,进程重启后用同一个 session_id 就能接着聊。不需要你自己管上下文历史。
流式输出:不用等它全部跑完
对于耗时较长的任务,run_stream() 让你实时看到 Agent 的进展:
async with AsyncCodyClient(workdir=".") as client:
print("开始分析...")
async for chunk in client.run_stream("分析整个仓库的架构,列出主要模块和依赖关系,给出改进建议"):
if chunk.type == "text_delta":
print(chunk.content, end="", flush=True)
elif chunk.type == "tool_call":
print(f"\n → {chunk.tool_name}", flush=True)
elif chunk.type == "done":
print(f"\n\n完成。{chunk.total_tokens} tokens,{chunk.duration_ms:.0f}ms")
用流式的场景:Web 应用需要 SSE 推送给前端、飞书机器人实时更新卡片(CodyClaw 就是这么做的)、命令行工具显示进度。
Builder 模式:把所有配置写在一起
如果你需要细粒度配置 Harness 参数,用 Builder 更清晰:
from cody.sdk import Cody
client = (
Cody()
.workdir("/path/to/project")
# 模型配置
.model("qwen3.5-plus")
.base_url("https://coding.dashscope.aliyuncs.com/v1")
.api_key("sk-xxx")
# Harness:熔断参数
.max_tokens(100_000)
.max_cost(5.0)
.max_steps(50)
# Harness:安全边界
.allowed_roots(["/path/to/project", "/tmp"])
.blocked_commands(["rm -rf /", "sudo rm", "curl -X DELETE"])
# Harness:上下文
.system_prompt_extra("函数不超过 50 行。异常统一用 AppError。")
# Harness:Skills
.skills_dirs(["./skills"])
.build()
)
所有 Harness 参数都在这里声明式配置,不需要手写一堆钩子和中间件。
注册自定义工具:扩展 Agent 的能力边界
Cody 内置 30 个工具,但你自己的业务逻辑需要自定义工具。注册很简单:
from cody.sdk import Cody
# 函数即工具,docstring 就是告诉模型这个工具干什么
async def query_production_db(ctx, sql: str) -> str:
"""在生产数据库执行只读 SQL 查询。只允许 SELECT 语句,禁止 DDL 和 DML。"""
if not sql.strip().upper().startswith("SELECT"):
return "Error: 只允许 SELECT 查询"
result = await db.execute(sql)
return result.to_json()
async def send_alert(ctx, channel: str, message: str, severity: str = "info") -> str:
"""向告警系统发送告警。severity 可选 info/warning/critical。"""
await alert_system.send(channel=channel, message=message, severity=severity)
return f"已发送 {severity} 告警到 {channel}"
async def deploy_service(ctx, service_name: str, version: str) -> str:
"""部署指定服务到预发环境。只能部署到预发,不能直接部署生产。"""
await k8s.deploy(service_name, version, env="staging")
return f"{service_name}:{version} 已部署到预发"
client = (
Cody()
.workdir(".")
.tools([query_production_db, send_alert, deploy_service])
.build()
)
注意几件事:
- 函数签名即接口定义,类型注解直接变成模型的参数 schema
- docstring 是给模型看的"工具说明书",写清楚边界很重要
- 工具里可以包含业务层面的约束(比如"只允许 SELECT")——这是 Harness 约束层的一部分
现在你可以用自然语言跑任务,Agent 会自己判断什么时候该调哪个工具:
result = await client.run(
"查一下生产数据库 users 表过去 7 天新增了多少用户,"
"如果超过 1 万发个 info 告警到 #data-team 频道"
)
存储抽象:替换底层实现
Cody 的所有持久化层都是可替换的——默认 SQLite,但可以注入自己的实现:
from cody.sdk import Cody
from cody.sdk.storage import SessionStore, AuditLogger
class RedisSessionStore(SessionStore):
"""把会话存在 Redis 里,支持横向扩展"""
async def save(self, session_id, messages): ...
async def load(self, session_id): ...
class PostgresAuditLogger(AuditLogger):
"""把审计日志写进 Postgres,方便做数据分析"""
async def log(self, event): ...
client = (
Cody()
.workdir(".")
.session_store(RedisSessionStore(redis_client))
.audit_logger(PostgresAuditLogger(pg_pool))
.build()
)
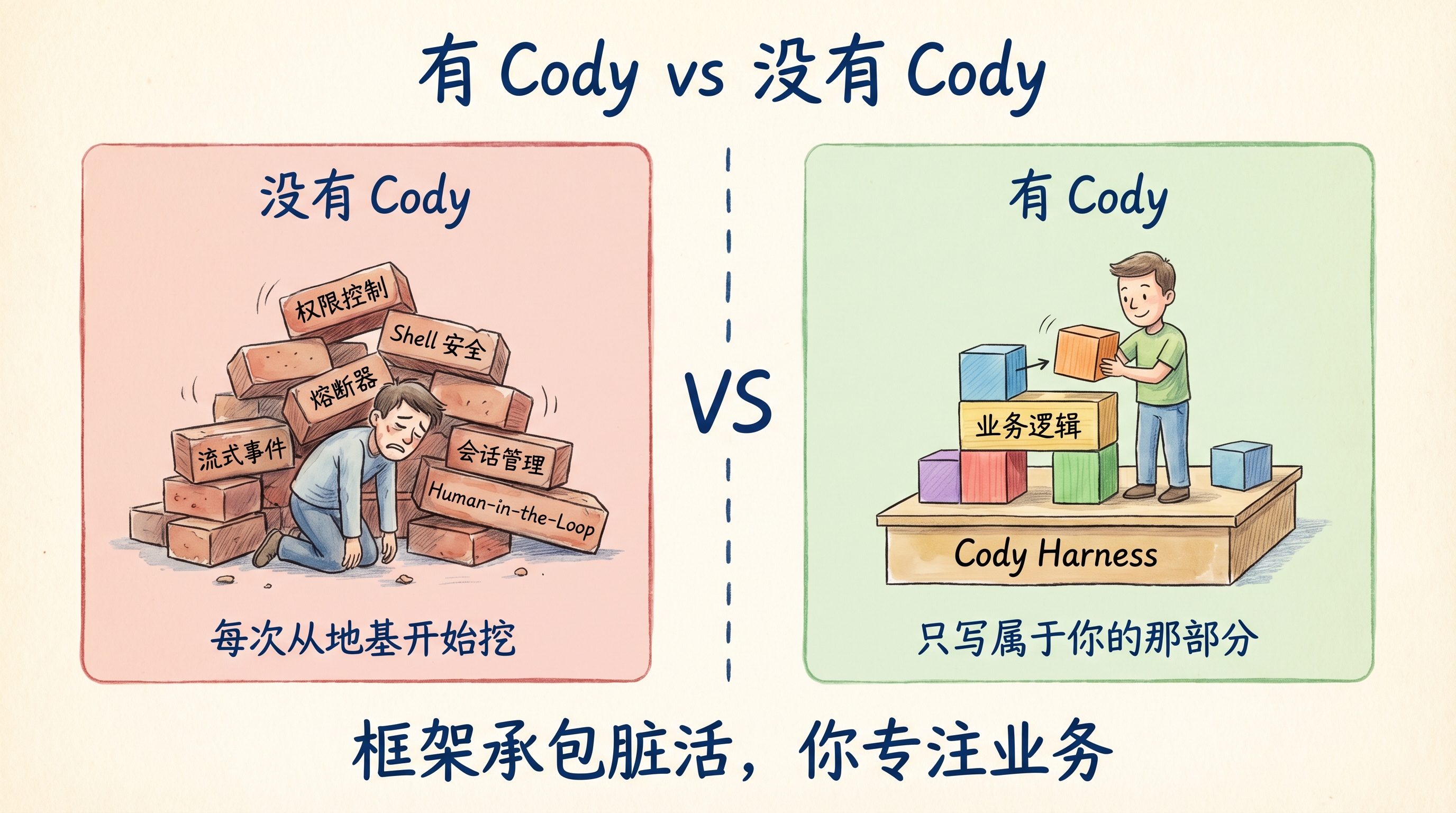
Harness 很重要,但搭 Harness 不应该是每次都从零开始
回到最开始的问题。
Harness 文章里说,好的 Harness 能把同一个模型的成功率从 42% 推到 78%,排名从 Top 30 推进 Top 5。这个结论是对的,Harness 很重要。
但 Harness 文章没说的是:搭这个 Harness 本身需要大量工程工作。
文件访问边界要手写路径检查,Shell 安全要手写命令解析,熔断器要手写计数器和中断逻辑,流式事件要手写 SSE 或 WebSocket,会话管理要手写数据库 schema 和 CRUD,Human-in-the-Loop 要手写状态机……这些东西全部跟你的业务逻辑无关,但每次造一个新的 Agent 应用都要从头实现一遍。
Cody 想做的是:把 Harness Engineering 方法论固化成一个开源框架,让每个做 AI Agent 应用的开发者都能直接站在一个结实的 Harness 上起步,而不是每次都从地基开始挖。
用 CodyClaw 举例:
# CodyClaw 的 Agent 执行层,整个就这么多
client = (
Cody()
.workdir(config.workdir)
.model(config.model)
.base_url(config.base_url)
.api_key(config.api_key)
.tools([*feishu_tools, *cron_tools])
.skills_dirs(["./skills"])
.max_tokens(200_000)
.build()
)
async for chunk in client.run_stream(user_message, session_id=session_id):
if isinstance(chunk, TextDeltaChunk):
accumulated_text += chunk.content
await update_feishu_card(accumulated_text)
elif isinstance(chunk, InteractionRequestChunk):
await send_feishu_approval_card(chunk.question, chunk.options)
CodyClaw 的 gateway 目录负责飞书接入、消息路由、会话管理、Cron 调度——这些是 CodyClaw 的业务逻辑。文件权限、Shell 安全、熔断、流式、Human-in-the-Loop——这些全在 Cody 里,CodyClaw 一行没写。
这就是框架的价值:把重复的脏活隐藏起来,让你只写真正属于你的那部分。
与现有方案的对比
既然聊到这里,说清楚 Cody 跟其他方案的差别。
LangChain:太重,抽象层太厚
LangChain 很全面,生态也很大。但你想做一件简单的事——"让 AI 读一个文件然后修改它"——需要理解 Chain、Runnable、AgentExecutor、PromptTemplate……一套下来,你可能比直接调 API 多写了三倍的代码,还不一定搭好了 Harness。
Cody 的哲学是:你直接告诉 Agent 该做什么,Harness 在底下默默工作,你感觉不到它的存在。
pydantic-ai:好底座,但不是 Harness
Cody 的 Core 底层用了 pydantic-ai——模型无关抽象和类型安全做得很好。但它解决的是"怎么跟模型对话",不解决"Agent 在真实环境里工作需要什么 Harness"。
文件权限边界、Shell 安全、熔断器、会话持久化、项目记忆、Skills 加载——这些都是 Cody 在 pydantic-ai 之上补的 Harness 层。
Claude Code / Cursor:Harness 做得很好,但封闭
这些产品的 Harness 做得确实扎实,但它们是封闭的。你没办法把它们的执行层嵌进自己的应用,没办法加自定义工具,没办法控制行为边界,没办法替换底层存储。
Cody 是 MIT 开源,可以看所有代码、改所有逻辑、嵌进任何 Python 应用——Harness 是你的,不是 Anthropic 或微软的。
目前的状态
Cody 现在是 v2.0.0,核心功能稳定可用:
- 650+ 测试用例,Python 3.10–3.13 全覆盖,CI 持续验证
- 30 个内置工具:文件 I/O、搜索、Shell 执行、LSP 代码智能、Web 抓取、子 Agent、MCP 调用、记忆管理
- 多模型支持:通义千问、Claude、OpenAI、DeepSeek、Google Gemini、智谱 GLM,以及任何 OpenAI 兼容 API
- MCP 协议支持:stdio 和 HTTP transport,可以接入任何 MCP 工具服务器
- LSP 代码智能:诊断、跳转定义、查引用、悬停文档,Agent 能做代码级别的理解
- Agent Skills:兼容 agentskills.io 开放标准,26+ AI 平台可复用同一套 Skills
文档在 GitHub,SDK 教程在 CodyCodeAgent.github.io/cody,有 13 篇从入门到进阶的完整教程。
最后
做 Cody 的出发点说起来其实很朴素:
Harness 那篇讲清楚了,好的 Harness 决定了 Agent 的上限。但每次造一个 AI Agent 应用都要从零搭 Harness,这件事本身就是重复劳动。
重复劳动该怎么处理?抽成框架。
Cody 就是这个框架。它不是要替代你,而是把搭 Harness 这件脏活承包了,让你可以把精力放在真正属于你的业务上——就像上一篇里,CodyClaw 的核心代码只有 800 行,因为另外那几千行 Harness 的活是 Cody 干的。
如果你也在造 AI Agent 应用,欢迎试试:
pip install cody-ai
GitHub 上点个 Star 是最好的反馈:github.com/CodyCodeAgent/cody