没有标准数据集,如何客观评测算法效果?

团队自研算法跑了好几年,最近出了新版本,小范围测下来感觉好不少。但要严谨地回答"到底好了多少",发现根本说不出来。这篇文章记录了我们从零搭评测体系的过程——方法论怎么选的,系统怎么设计的,中间踩了哪些坑。
一、问题从哪里来
事情起因很简单。团队做了多年的自研算法,线上跑着的版本一直还行,不算拉胯。后来花了几个月搞了个新版本出来,从原理上应该更准。我们自己内部试了几十条 case,肉眼看确实好了不少。
然后老板问了一句:能不能证明新算法更好?好多少?
我们当时是真答不上来。
你可能觉得——这不简单嘛,拿一批标准数据跑一下,算个准确率对比不就完了?问题就出在这儿:我们没有标准数据集。准确地说,我们有大量历史数据,但这些数据的标签全是当前在线算法自己打的。用老算法的判断去评测新算法,这就好比让被告当法官,怎么判都说不清。
老算法说某条数据应该是 A 类,新算法说应该是 B 类——到底谁对?没有第三方来裁,这个问题永远扯不清。
而且仔细一想,这不只是一个"数据从哪来"的问题。背后暴露出来的是整套评测能力的缺失:
- 历史标注都是算法自产的,拿来做评测基准不中立
- 全靠人工从头标注,几百条可能还行,上千条就扛不住了——又贵又慢
- 每次版本对比都是临时攒的评测方案,评完就扔,下次再来一遍
- 最后拍板切不切算法,基本还是靠感觉和几个核心 case 的表现
说白了,我们连"评测"这件事本身都没有个标准化的流程。
二、调研了一圈,业界是怎么干的
意识到问题以后,我们花了大概两周去看业界的做法。不看不知道,一看发现这其实是个经典问题——特别是在 NLP 和推荐系统领域,很多团队都踩过类似的坑。
我们看到的方法大概可以分成五类,下面逐个聊聊,包括它们各自的适用场景和局限。
1. LLM-as-Judge:让大模型来当裁判
最近两年很火的一个思路。核心想法是:既然人工标注太贵,能不能让一个足够强的大模型来代替人做判断?
学术界做得比较早的是 MT-Bench(Zheng et al., NeurIPS 2023),他们发现 GPT-4 和人类专家在打分上的一致率超过 80%。听起来不错,但这 80% 的数字需要注意几个前提:他们的任务是多轮对话质量评估,评分维度定义得非常清晰,而且用的是 GPT-4 这个级别的模型。换到我们自己的业务场景,一致率会是多少,还真不好说。
我们后来自己做了个小实验,拿了 50 条数据,人工标注完以后让 GPT-4o 也标一遍——一致率大概在 73% 左右。不算低,但也没高到可以完全信赖。
LLM 当裁判还有几个已知的偏见问题,学术界总结得比较全面了:
- 位置偏见(Position Bias):把两个算法的输出放在一起让 LLM 比较,它倾向于选排在前面的那个。MT-Bench 的论文发现,交换两个答案的顺序,有大约 15%-25% 的情况 LLM 会改变判断。应对办法是每次比较都跑两遍,交换顺序,两次结果一致才算数。
- 长度偏见(Verbosity Bias):答案越长越容易拿高分,哪怕多出来的都是废话。这个在 G-Eval(Liu et al., EMNLP 2023)里也有讨论。解决办法是在评分 prompt 里明确写"不要因为回答更长就给更高分",但说实话效果有限,只是缓解。
- 自我偏好(Self-Enhancement Bias):LLM 更倾向于给和自己风格接近的回答更高的分。比如用 GPT-4 当裁判,它可能对 GPT-3.5 的输出更宽容,对 Claude 的就稍微严一点。解决办法是换不同家族的模型来交叉评判。
说完局限,说一下对我们来说最有用的点。我们最终决定用 LLM-as-Judge,但不是直接拿它的判断当最终答案。而是反过来用——让 LLM 和在线算法同时对一批数据做判断,然后把两者意见不同的 case 挑出来,交给人工去仲裁。这样 LLM 等于帮我们做了一遍初筛,人工只需要处理有争议的部分,标注量一下子降了很多。
2. 弱监督(Weak Supervision):多个不靠谱的信号,组合起来可以挺靠谱
数据量再大一些的时候,逐条过 LLM 裁判的成本也不低(调 API 也花钱嘛)。弱监督的思路是:找到多个"不完美但有一定区分度"的信号源,让它们联合投票。
举个例子,我们场景下可用的信号源大概有这些:
- 在线算法的判断——准确率估计在 70% 左右
- GPT-4o 的判断——准确率估计在 85% 左右
- 一些简单的规则,比如"两段文本长度差超过 3 倍"——准确率可能只有 60%
单拎出来哪个都不够可靠。但斯坦福搞的 Snorkel 框架(Ratner et al., VLDB 2018)做了一件巧妙的事:它不需要标准答案,只要看这些信号之间是"经常同意"还是"经常打架",就能反推出每个信号源大概有多靠谱,然后做加权投票。原论文在几个公开数据集上的实验显示,这种方式能把准确率从单信号源的 60%-80% 提升到 85%-95%。Google 后来在内部做了个叫 DryBell 的系统(2019),把 Snorkel 的思路在工业规模落地了。
不过弱监督也有它的问题。最大的前提假设是各信号源之间要"条件独立"——也就是说它们犯错的时候不能总是同时犯同一个方向的错。但在实际业务里,不同算法的错误模式往往是高度相关的(比如大家都对某一类短文本判断不好),这会影响 Snorkel 的推断准确性。论文里承认了这个问题,给的建议是在信号源的选取上尽量引入"异质性"——比如一些基于语义的,一些基于统计特征的,一些基于规则的。
所以 LLM-as-Judge 和弱监督其实是互补的:前者解决的是"谁来判断对错"的质量问题,适合少量数据精细评判;后者解决的是"怎么批量打标"的规模问题,适合大量数据粗标。
3. 主动学习(Active Learning):先标最值钱的数据
标注预算有限,肯定不能什么数据都标。哪些数据标了收益最大?
主动学习的核心观点是:标那些模型最"拿不准"的数据。道理很直观——你做一套卷子,一眼就会的题看了答案也没什么收获;但那道想了半天写不出来的题,看了答案可能一下子就通了。
在评测场景下有一个很自然的适配:让多个算法版本同时对一批数据做判断,优先标注那些各版本意见分歧最大的 case。这在学术上叫 Query-by-Committee,也叫分歧采样(disagreement sampling)。Settles(2009)有一篇综述把各种主动学习策略做了比较全面的梳理。
我们内部讨论的时候,有同事一开始觉得这不就是"cherry-picking 难的 case 来标"嘛——确实有这个味道,但关键区别在于:难 case 不是人主观挑的,而是算法之间的分歧自动暴露出来的。
不过主动学习也有一个实操层面的坑:如果只标分歧大的 case,你的评测集会严重偏向"困难样本",整体评测结果会显得各算法都不太行。所以在实际操作中,我们还是会混入一定比例的随机抽样数据,让评测集的分布不至于太偏。学术上把这个叫 exploitation-exploration tradeoff,和推荐系统里的冷启动问题本质上是一回事。
4. ELO 评分:没有标准答案也能排名
这个概念大家可能比较熟——王者荣耀、国际象棋的排名系统背后就是 ELO。它的精髓在于:不需要知道每个选手的"绝对水平",只需要积累大量两两对比的胜负记录,就能推算出全局排名。
LMSYS 搞的 Chatbot Arena(2024)把这套机制用到了 LLM 评测上,效果很好。用户在平台上给两个匿名模型的回答投票,积累了上百万次比较之后,排行榜和人工全面评测的结果高度吻合。
我们觉得 ELO 在项目早期特别有用——标准数据集还没攒够的时候,先让各版本算法两两 PK,由 AI 裁判来判胜负,跑个几百轮,至少能给出一个大致的相对排名,辅助决策。
具体操作上,我们让各版本算法对同一条数据分别给出判断和推理过程,然后由 LLM 裁判选"哪个推理更靠谱"。注意这里不只是看结论对不对——两个算法可能都给出了正确结论,但一个是真的理解了语义逻辑,另一个只是碰巧命中了某个关键词。光看结论根本分不出来,看推理过程才能区分。
不过 ELO 也有局限。第一,它给出的是排序而不是绝对分数,你没法说"A 算法准确率 92%"。第二,ELO 对比赛场次的需求量不小,文献里一般建议至少需要 200-400 次有效对局才能收敛到比较稳定的排名。第三,如果几个算法水平非常接近,ELO 的区分度会变差,这时候还是得上标准数据集来做精细对比。
5. 数据飞轮(Data Flywheel):把前四个方法串成一个循环
前面四个方法各管一摊,但单独哪一个都不能完整解决问题。所谓"数据飞轮",其实不是一个新方法,而是一种组织方式——把上面这些方法连成一个会自我强化的闭环。
概念上类似 Tesla 的自动驾驶数据飞轮:线上数据收集 → 自动标注 → 模型训练 → 上线 → 收集更多数据。每转一圈,数据质量和模型效果都会好一截。
微软 2024 年发了一篇 Arena Learning 的论文,做得比较激进——直接用 AI 模拟对战替代人工投票,论文里报告的数字是效率提升 40 倍,和人类判断的一致率达到 98.79%。不过这个数字是在他们的特定实验设置下得到的(评测对象是 LLM 的多轮对话能力),迁移到其他场景不一定能复现这么高的一致率。
对我们来说,飞轮的关键不在于一步到位跑通所有环节,而在于让整个系统有一个持续改进的机制——每一次评测都能沉淀新的标准数据和难例,每一次难例分析都能改进 AI 裁判的能力。
三、我们的设计:自举评测飞轮
搞清楚各方法的优劣之后,我们开始设计自己的方案。核心思路可以叫做"自举(Bootstrapping)评测飞轮"——从零开始,先用 LLM 帮忙生产第一批标准数据,然后在这个基础上不断迭代。
整体流程大概是这样:
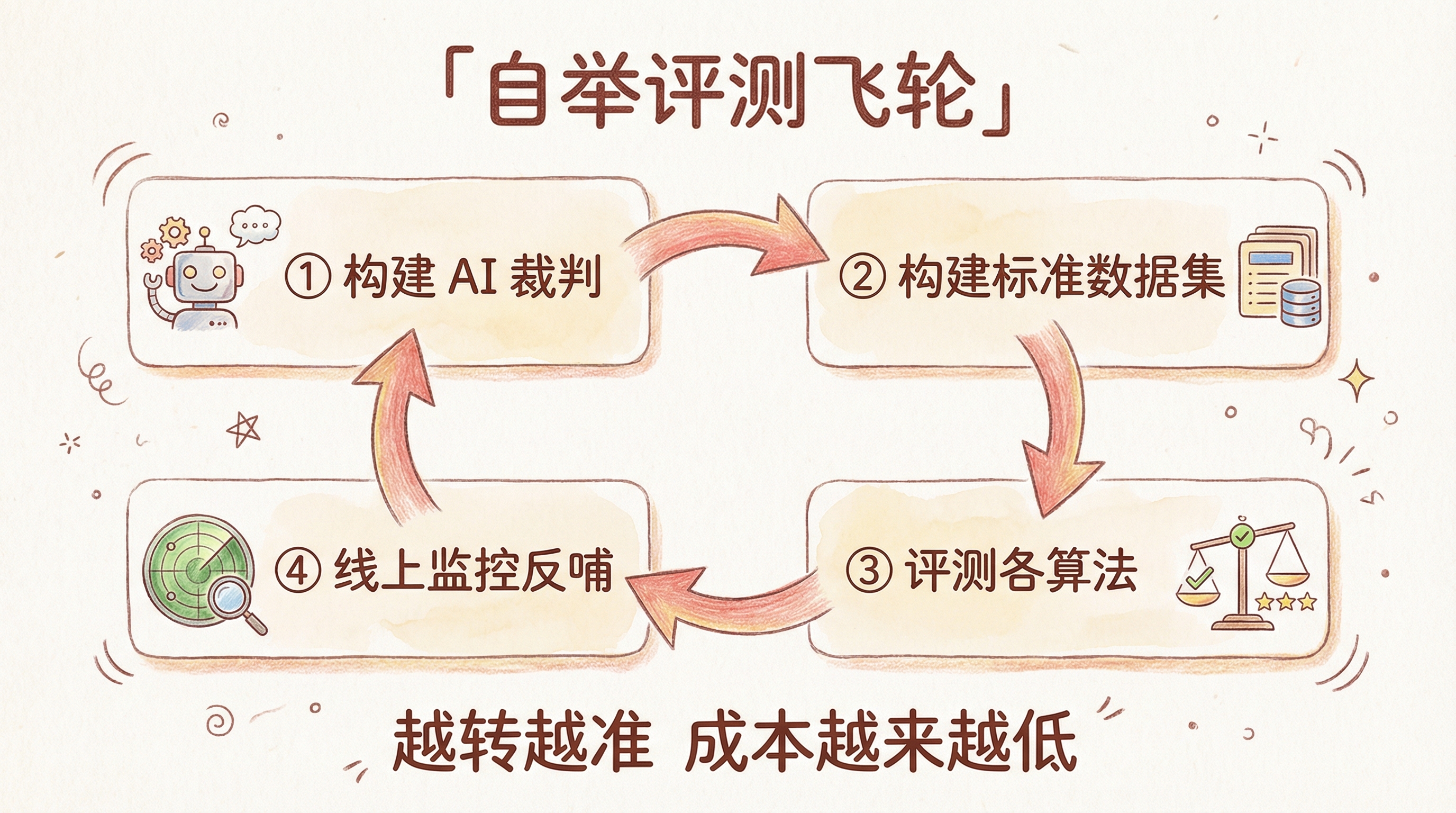
整个体系围绕一个 AI 裁判 Agent 来转。这个 Agent 不是写死的打分脚本,而是一个可以持续调优的东西——它的 prompt 里包含了评分维度、细则、以及不断积累的领域判断 skill:
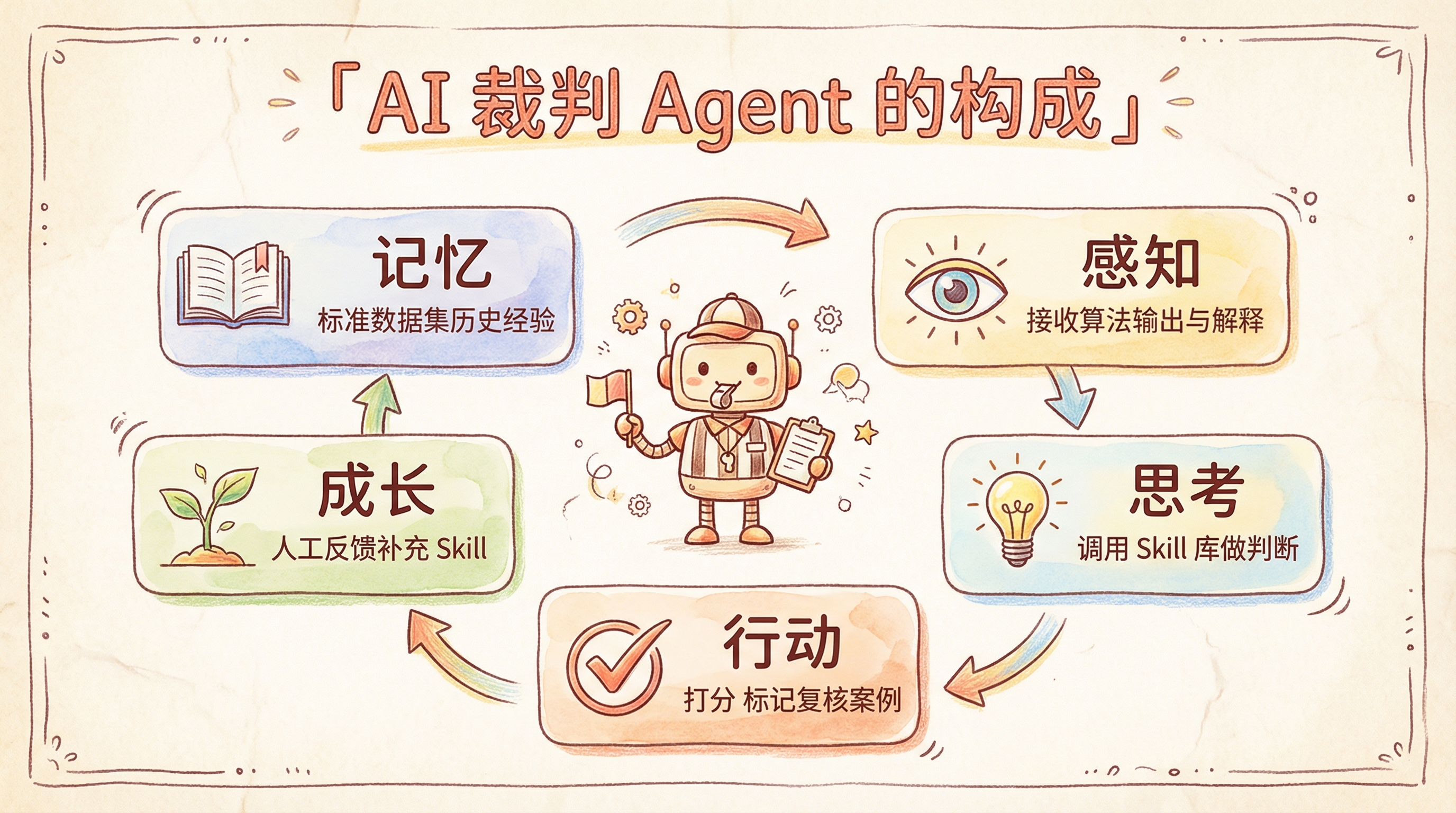
为什么要把 AI 裁判做成可持续迭代的 Agent,而不是一个固定的 prompt?因为我们在实际标注中发现,AI 裁判犯错往往集中在某几类 pattern 上——比如某些领域术语的理解、某些边界情况的判断逻辑。每发现一类典型错误,就可以针对性地往 prompt 里加一条 skill 来纠正。时间一长,AI 裁判在特定业务场景下的准确率会逐步逼近甚至超过通用大模型的基线水平。
四、系统模块
完整系统的模块构成如下:
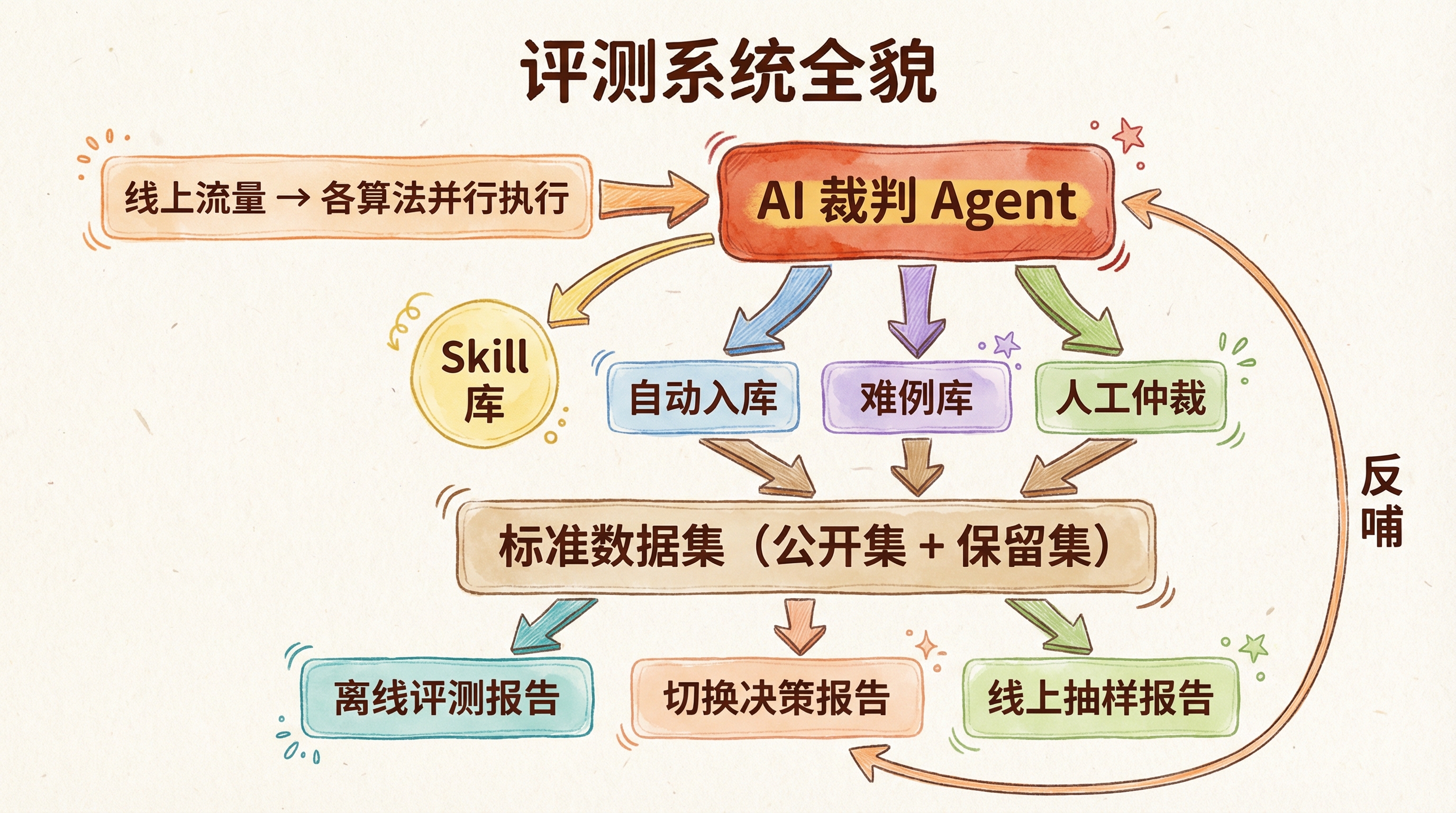
这里面有几个设计决策是我们内部讨论比较多的,单独说说:
标准数据集分成公开集和保留集。 公开集给算法开发者当开发测试用,保留集只在正式评测时才拿出来。这样做是为了防止算法开发者有意无意地针对评测集做优化——说难听点就是"刷榜"。Kaggle 竞赛里的 public/private leaderboard 就是同一个道理,搞过 Kaggle 的应该都深有体会:public 排行榜上排名靠前的方案,切到 private 上经常大幅掉分。
难例库要单独管理。 各版本算法分歧特别大、人工标注也觉得纠结的 case,单独放一个池子。这批数据是整个系统里最有价值的部分——它决定了 AI 裁判的能力天花板在哪里,也是算法改进最该优先攻关的方向。一开始我们没有做这个分离,所有数据混在一起,后来发现 AI 裁判在简单 case 上准确率 95% 以上,但在这些难例上只有 60% 左右,整体指标看着还行但其实掩盖了问题。
评测结果必须绑版本号。 AI 裁判本身在不断迭代,标准数据集也在扩充。如果不把每次评测结果和当时用的裁判版本、数据集版本绑定在一起,过一段时间回头看,历史评测数据就完全没法比较了。这个教训是血淋淋的——我们第一次对比实验做完了,觉得效果不错,准备写报告时发现中间更新过一次 AI 裁判的 prompt,导致前后的打分标准不一致,整个实验不得不重跑。
五、落地路径
MVP:先回答"新算法是不是比当前的好"
一开始别想着搭完整系统,先把最紧迫的问题解决掉——给算法切换提供一个说得过去的依据就行。
- 定评分维度:这一步比想象中难。我们一开始定了 8 个维度,后来发现太细了,标注人员经常在几个相似维度之间纠结,最后砍到 4 个,反而一致性更高。
- 搭基础 AI 裁判:把维度和评分细则写进 prompt,先跑通单条数据的打分。这里建议用 few-shot 而不是 zero-shot——给几个标注好的示例,准确率能提升不少。
- 采集 300-500 条数据:大头来自各版本算法分歧大的 case,小部分随机抽取。纯随机抽样在信息量上太浪费了,但完全不做随机又会有偏。我们最后的比例大概是 7:3。
- 人工标注:这一步偷不了懒。标注人员必须有领域判断能力,找几个实习生随便标一下是出不来好数据的。我们的做法是找了 3 个业务方向的资深同事交叉标注,一致率作为数据质量的参考指标。
- 跑对比评测:让 AI 裁判对各版本输出打分,人工复核那些 AI 裁判自信度低的 case。
- 迭代 AI 裁判:归因它的错误,分析是哪一类 case 判不好,针对性地补 skill。我们设了个及格线是准确率 85%,不到就继续迭代,到了就先往下走。说实话这个阈值有点主观,但总得有个止损点,不然会陷入无限打磨的循环。
- 输出决策报告:指标对比表 + 典型 badcase 分析 + 切换风险评估。给老板看的那种。
第二阶段:扩充评测基准
- 把 MVP 阶段发现的难例整理进难例库,对高频错误类型做专项突破
- 引入弱监督的方式批量生产初始标签,减少对纯人工标注的依赖
- 标准数据集正式切分为公开集和保留集
第三阶段:跑起来,让飞轮转
- 从线上流量里分层抽样,自动灌进评测流程
- 定期(比如每周)自动出质量报告,设好报警线——如果某个指标跌破阈值自动通知
- 线上新发现的难例自动进入难例库,人工复核结果反哺给 AI 裁判
- 上 ELO 排行榜,作为标准数据集评测的补充视角
六、几个讨论中的争议点
整个方案不是一拍脑袋想出来的,中间经历了好几轮内部讨论。有些点一开始团队里有不同看法,聊完以后觉得值得记下来。
LLM 的角色到底是什么? 很多人听到 LLM-as-Judge,第一反应是"用 AI 替代人工打分"。但我们实际操作下来发现,至少在现阶段,LLM 更适合当"数据生产的辅助工具"而不是"最终裁判"。具体说就是:让 LLM 和在线算法同时跑一批数据,把两边结论不同的 case 挑出来给人工仲裁。LLM 扮演的是"高效初筛器"的角色,而不是"权威判定者"的角色。这个定位区分挺重要的,不然容易对 LLM 的判断给予过高信任。
ELO 应该什么时候上? 直觉上会觉得 ELO 这种"没有标准答案也能排名"的机制是更高级的评测方式,应该等体系成熟了再引入。但聊了一圈以后发现恰恰相反——ELO 最适合的是早期阶段,标准数据集还没攒够的时候,先用 ELO 做一轮两两对比,至少能给出一个粗排名,比什么都没有强。等标准数据集建起来了,反而应该以标准数据集上的绝对指标为主,ELO 退居辅助。
只看结论够不够? 如果两个算法版本在某条 case 上都给出了正确结论,是不是就算打平?我们的答案是不够。比如做文本分类,一个版本是真正理解了文本语义后给出的分类,另一个只是因为匹配到了某个高频关键词。两者都答对了,但碰到一个没有那个关键词的新 case,后者很可能就翻车了。所以我们的评测不只看"结论对不对",也会评"推理过程合不合理"。这当然增加了评测的复杂度,但为了判断泛化能力,值得。
方案的局限在哪? 坦率说,这套方案有一个根本性的循环依赖:我们用 LLM 来帮助生产标准数据,又用标准数据来评估 AI 裁判的准确率。如果 LLM 在某类问题上有系统性偏差,而这类偏差恰好人工也不容易发现,那整个评测体系就可能在这类问题上有盲区。我们的应对策略是:定期做一轮纯随机抽样的人工全量标注(规模不大,比如 100 条),作为 sanity check,看看 AI 裁判有没有出现系统性的偏移。
七、总结
回过头看,整个方案的核心思路其实不复杂:
我们的困境是"没有标准数据集就没法评测",但标准数据集不会从天上掉下来。所以我们选择了一条自举的路——先借助 LLM 和人工配合,从零开始攒第一批标准数据;然后在这个基础上搭建 AI 裁判,用主动学习来决定标哪些数据收益最高,用弱监督来降低大规模打标的成本,用 ELO 在数据不足时给出早期排名。所有这些环节串在一起,形成一个不断自我改进的飞轮。
这套方法论不是我们发明的,每个环节都有成熟的学术研究和工业实践做支撑。我们做的只是把它们组合起来,适配到自己的场景里。过程中踩了不少坑,也有很多妥协——比如 AI 裁判 85% 的准确率到底够不够,比如难例库要不要单独管理,比如保留集多大比例合适——这些问题说实话没有标准答案,我们也是边做边调。
如果你的团队也在面对类似的困境——有自研算法但缺少客观评测手段——希望这篇文章能提供一些参考。不一定要照搬全套方案,从 MVP 开始,先让飞轮的第一个环节转起来就行。
飞轮这东西,推第一下是最费力的。但只要它开始转了,后面就会越来越顺。
参考文献
- Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena(Zheng et al., NeurIPS 2023)
- G-Eval: NLG Evaluation using GPT-4(Liu et al., EMNLP 2023)
- Snorkel: Rapid Training Data Creation with Weak Supervision(Ratner et al., VLDB 2018)
- Active Learning Literature Survey(Settles, 2009)
- Chatbot Arena: An Open Platform for Evaluating LLMs(LMSYS, 2024)
- Arena Learning: Build Data Flywheel for LLMs Post-training(Microsoft Research, 2024)